发布时间: 2024-08-07 10:06:39
1.数据库概述
1.1背景信息
SEER数据库(Surveillance, Epidemiology, and End Results,监测、流行病学和最终结果)是由美国国立癌症研究所(NCI)创建并维护的一个大型公共数据库,数据获取方便并且公开免费,深受广大肿瘤领域科研工作者的喜爱。该数据库记录了美国部分州县上百万名恶性肿瘤患者的发病率、死亡率和患病情况等信息,主要提供了临床资料,如性别、年龄、种族、地理位置、婚姻状态、肿瘤大小、肿瘤病理、肿瘤偏侧、肿瘤WHO分级、TNM 分期、肿瘤部位等,为缺少临床科研数据的临床研究者提供了很好的数据来源。自1973年创建以来,SEER数据库已经成为全球最全面的癌症数据资源之一。
1.2数据库用途
SEER数据库样本量大,统计学效能强,这使基于SEER数据库的研究具有较高的临床参考价值,被广泛用于癌症研究、公共卫生规划、政策制定和教育。
1.3数据采集方式
SEER数据库的数据通过一系列严格的收集和报告程序获得,涉及多个癌症登记处。数据来源包括医院、门诊诊所、病理实验室和其他医疗机构。调查详情可以在SEER官方网站的方法与工具栏目进行查看。
1.4样本特征
SEER计划始于1973年1月1日。在过去的50年里,地理面积和人口覆盖率都有所扩大,占当今美国人口的近50%。SEER数据库的样本涵盖了不同年龄、性别、种族和社会经济背景的人群,特别关注少数族裔和其他弱势群体,以确保数据的代表性和全面性。SEER人口与美国总人口特征比较,SEER人口中外国出生人口的比例往往高于美国普通人口。
2.使用方式
2.1
访问与获取
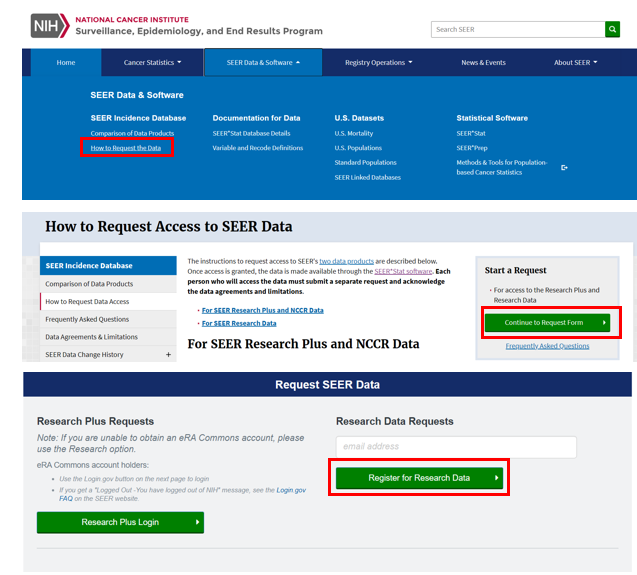
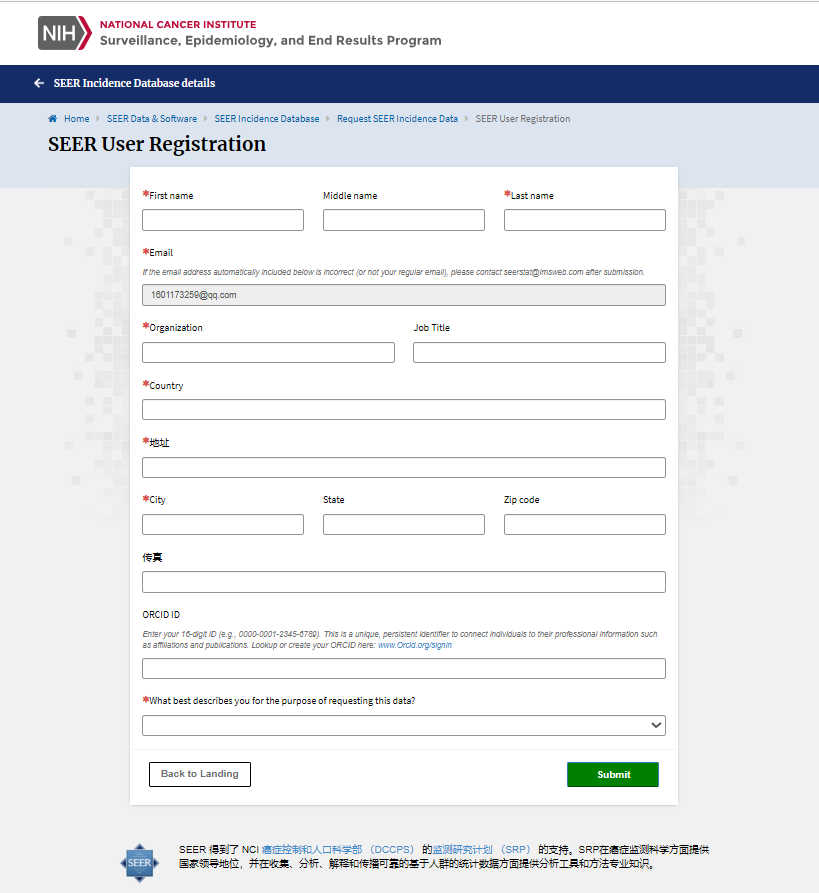
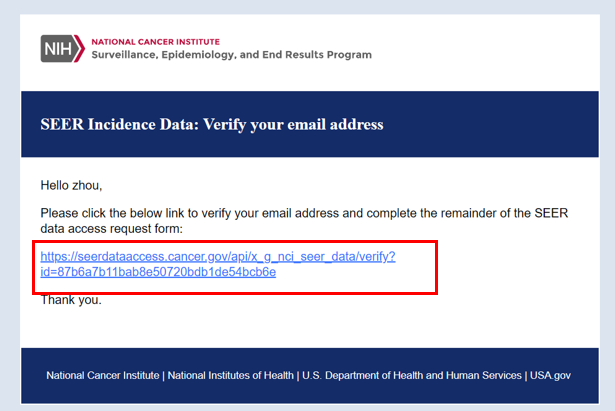
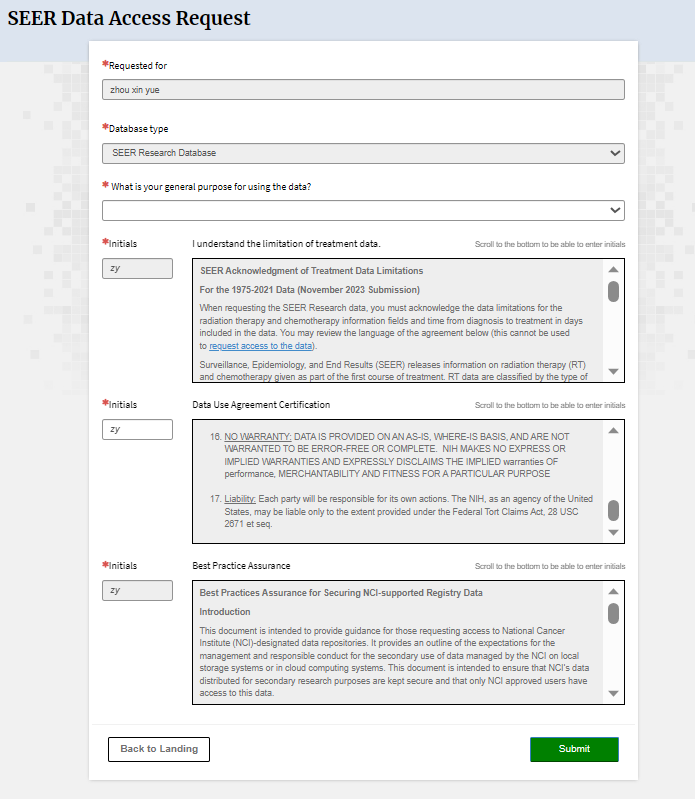
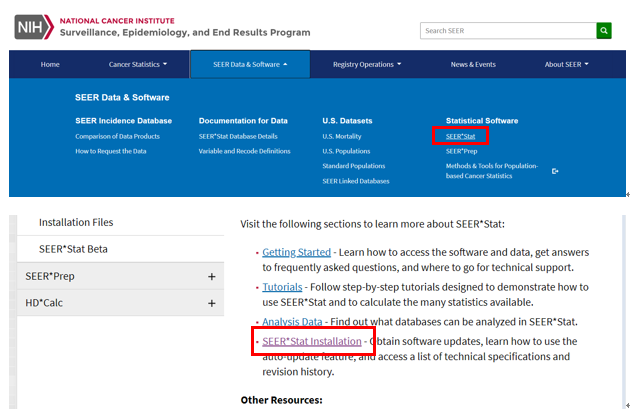
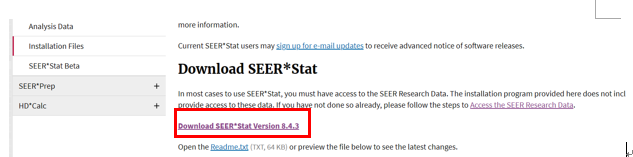
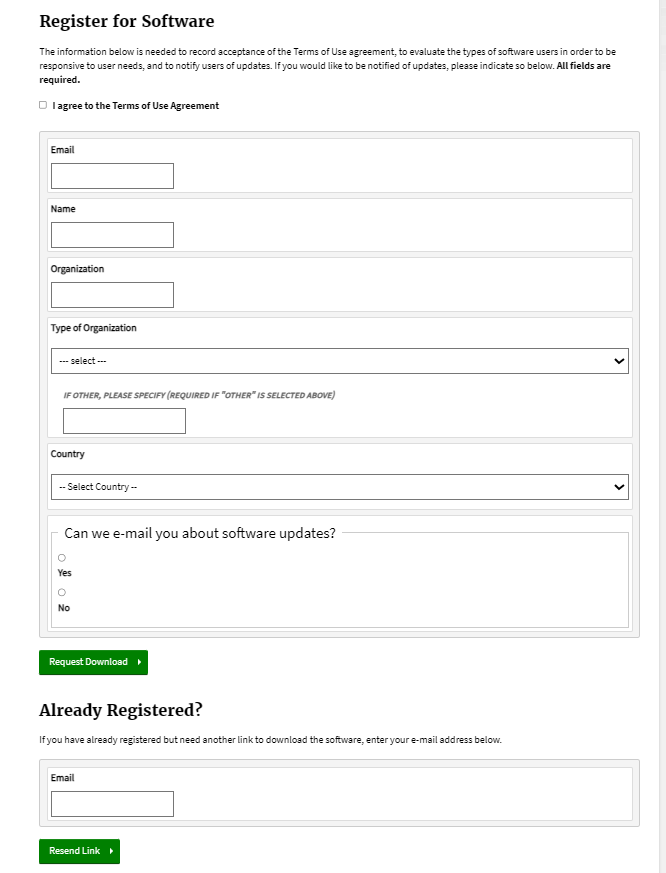
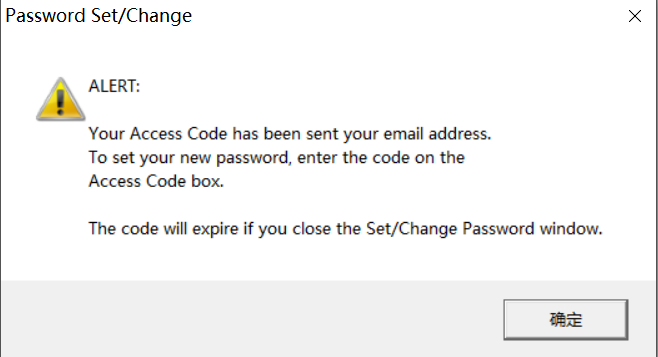
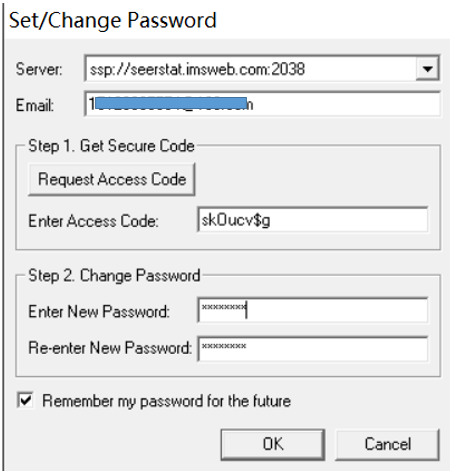
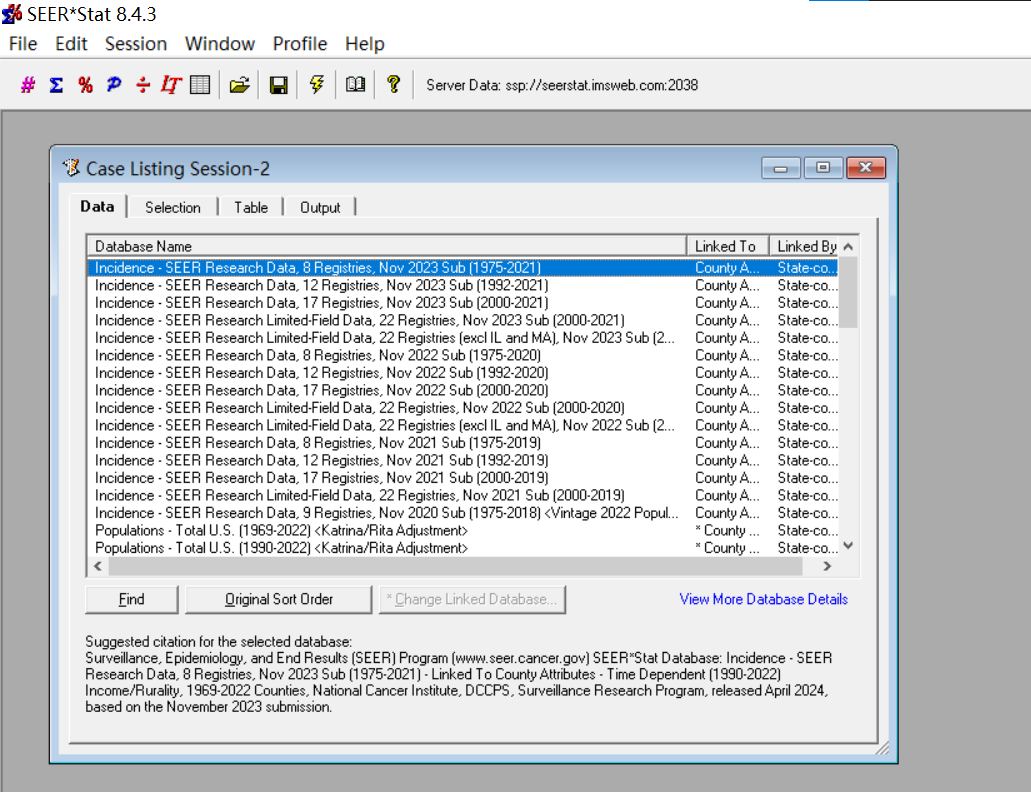
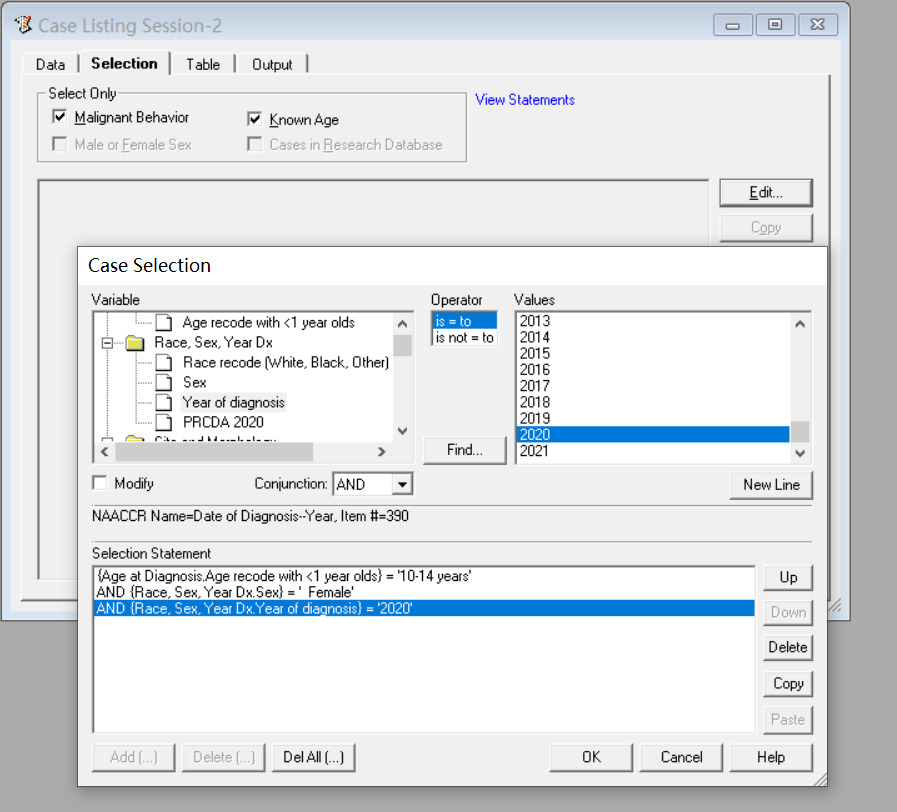
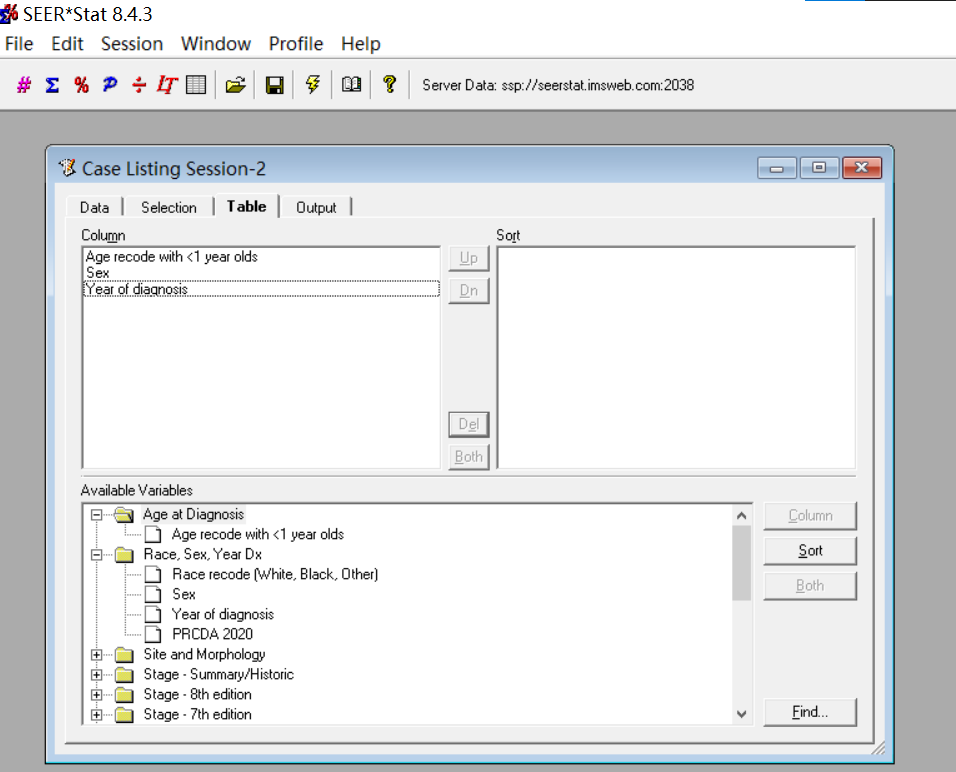
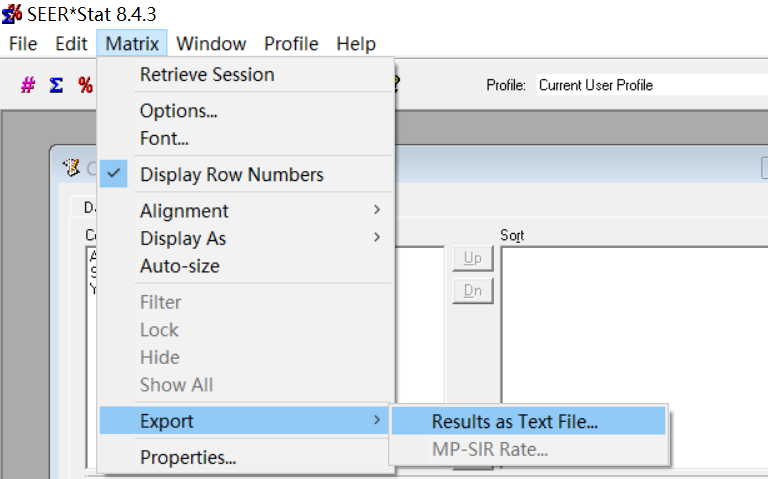
数据库在每年11月对提交数据进行质控检测,并在来年4月开放,更新会在官网显示,若需要重新申请权限会以邮件提示。SEER数据库提供了一个在线查询系统SEERStat,研究人员可以通过这个工具访问和分析数据。用户需要先下载并安装SEERStat软件,然后申请访问权限,通过这个平台可以自定义查询条件,提取相关的统计数据进行分析。通过邮箱进行注册登录,进行相关操作。
2.2
数据使用指南
3.数据类型
3.1
数据信息
包括患者的注册编号、个人信息、原发病灶部位、肿瘤尺寸、肿瘤编码、治疗方案、死亡原因等。
3.2
数据范围
9大类肿瘤:乳腺、结肠&直肠、其他消化系统、女性生殖、淋巴&白血病、男性生殖、呼吸系统、泌尿系统及其它尚未确指的类型。
4.研究案例
#4.1研究案例(一)
2023年10月16日中国医科大学附属第四医院普外科学者在《PLoS One》(二区top, IF=2.9)发表题为:“Competing-risks model for predicting the prognostic value of lymph nodes in medullary thyroid carcinoma”的研究论文。文章基于SEER数据库1998 - 2016年诊断为MTC的患者资料,建立Cox比例风险和竞争风险模型,回顾性分析相关因素对淋巴结的影响。结果表明,在排除竞争风险后,淋巴结数量、阳性数量和阳性比例是甲状腺髓样癌预后不良的因素。
#4.2研究案例(二)
2023年10月12日新疆医科大学第一附属医院妇科,中亚高发疾病发病机制与防治国家重点实验室学者在《BMJ Open》(二区top, IF=2.4)发表题为:“Establishment of prediction models to predict survival among patients with cervical cancer based on socioeconomic factors: a retrospective cohort study based on the SEER Database”的研究论文。文章基于SEER数据库2007年至2011年间诊断为宫颈癌的5954例患者的数据。采用单因素和多因素Cox比例风险模型估计和分析社会经济因素与宫颈癌患者总生存期(OS)的相关性,构建和验证基于社会经济因素预测宫颈癌(OS)的预测模型。结果表明,与单独的AJCC分期系统相比,基于社会经济因素和AJCC分期系统的预测模型在预测宫颈癌OS方面具有较好的效果。
#4.3研究案例(三)
美国马萨诸塞州波士顿塔夫茨大学医学院圣伊丽莎白医学中心医学系学者在《Breast Cancer Res Treat》(二区top, IF=3.0)发表题为:“Survival analysis of patients with brain metastases at initial breast cancer diagnosis over the last decade”的研究论文。文章基于SEER数据库2010至2019年IV期乳腺癌患者信息,采用多变量逻辑回归分析初次乳腺癌诊断时脑转移的预测因素,使用Kaplan-Meier方法估计OS,并使用log rank检验比较组间差异,利用Cox回归评估几个变量与OS之间的关联。结果表明,在过去十年中,脑转移患者在初次诊断乳腺癌时的中位OS仍然很差。除肿瘤亚型外,OS还根据年龄、颅外转移和社会人口学因素而变化。
END




上一篇:40% 的 GDM 妈妈们都有这种困扰,你中招了吗?
下一篇:左手宏基因组学,右手代谢组学,左右开弓以揭示胃食管反流病儿童的肠道菌群与血清代谢物的关联