
发布时间: 2025-06-20 09:29:32
2025年6月12日,Tobias Gauss等人在《The Lancet Regional Health》杂志上发表了一篇题为《Comparison of machine learning and human prediction to identify trauma patients in need of hemorrhage control resuscitation (ShockMatrix study): a prospective observational study》的文章。机器学习可以改善对需要止血复苏(HCR)的创伤患者的及时识别,但现实生活中的表现仍未知。本研究旨在评估并比较机器学习算法与临床医生在预测创伤患者是否需要出血控制复苏(Hemorrhage Control Resuscitation, HCR)方面的预测性能。
一、研究背景
及时识别创伤患者是否需要HCR一直是临床上的重大挑战。由于识别不及时常常导致输血和止血操作延迟,从而影响患者的生存率。此外,不一致的决策也会导致偏离循证指南,影响治疗质量。尽管目前存在多种临床评分系统和流程图,但它们通常是为预测大出血而设计,性能有限,且难以融入日常实践。机器学习因其可处理缺失数据、自动化与实时预测的优势,被认为是一种更可靠的替代方案。然而,现有研究大多基于回顾性数据,缺乏前瞻性、真实世界的验证。因此,该研究意在填补这一空白。
二、数据来源
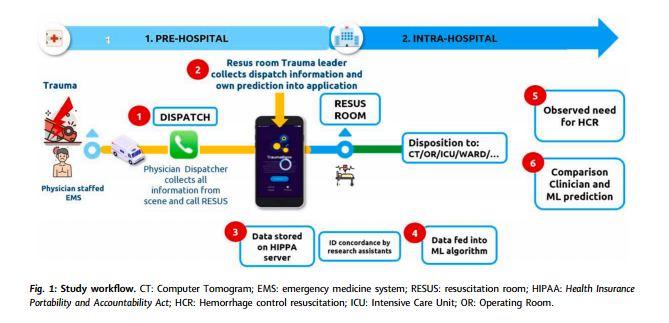
本研究基于2022年8月至2024年6月在法国8家一级创伤中心开展的前瞻性观察队列。凡由院前调度医生根据国家三级启动标准(A/B/C级)激活创伤团队的初诊患者,均符合纳入标准。共筛查5550例患者,依据既定排除标准(包括年龄<18岁、院前心脏骤停、二次转运及关键信息缺失等)剔除3966例,最终纳入1292例进入分析。数据通过定制的智能手机应用实时采集,创伤医生在接到预警电话后立即输入9项院前变量,并提供对HCR需求的主观概率预测(以百分比形式)。所有预测均在患者入院前完成并由时间戳记录,入院后填写的条目被排除。所使用的预测变量与机器学习模型完全一致,确保了人机比较的科学性与可比性。图1说明了研究工作流程。
三、研究方法
模型严格使用院前变量,经Shapley值评估后选定9个关键预测变量:创伤类型(钝性或穿透性)、最低舒张压和收缩压、最大心率、毛细血管血红蛋白浓度、给予的晶体液体积、插管状态、儿茶酚胺使用和临床明显的骨盆创伤。开发流程中,数据划分为训练集(50%)、验证集(20%)和测试集(30%),连续变量缺失值以均值填补并引入缺失数据掩码。通过比较分类与回归树(CART)、随机森林、极限梯度提升(XGBoost)和类别梯度提升(CatBoost)四种算法,选择XGBoost是基于10倍交叉验证中F4评分的优异性能。验证集用于确定最佳阈值和超参数。使用敏感性、特异性、准确性、精确性、召回率、AUCPR、AUC-ROC、似然比(阳性和阴性)和F4评分等指标在测试集中评估最终模型。使用2000次Bootstrap迭代计算1000名患者的样本量,以确保F4评分的置信区间下限低于人类参考0.63。来自Traumspel网络的20名临床医生专家组成的小组确定了0.11的决策阈值。所有模型开发均在Python 3.11.0中执行。
四、结果
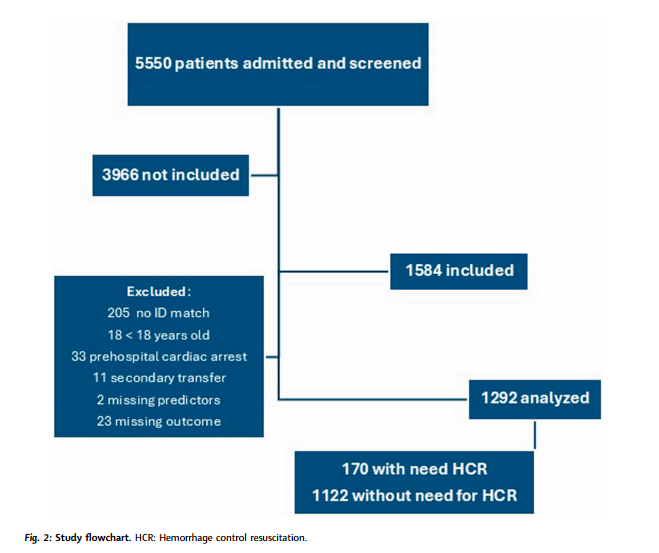
在2022年8月1日至2024年6月30日期间,纳入了5550名符合条件的患者中的1584名,其中1292名进行了分析。智能手机应用程序和临床记录之间共有205例无法匹配,其中87例被排除在外(图2)。
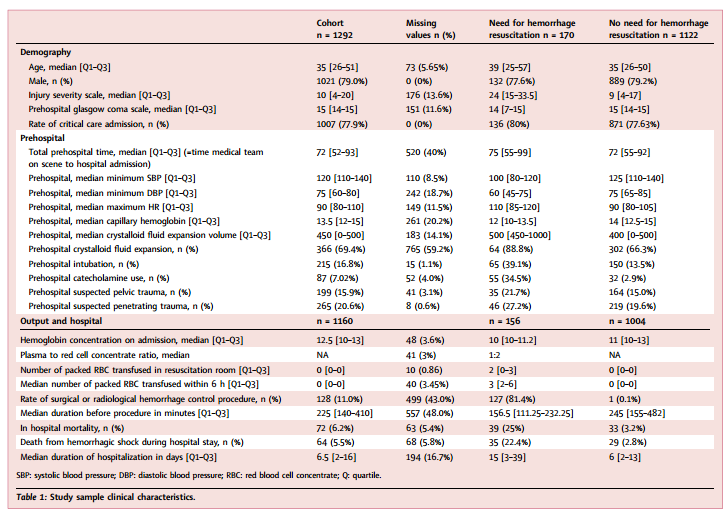
大多数患者为男性,中位年龄为35岁(IQR:25-51),ISS评分为10(IQR:4-20)。在1292名患者中有170名(13%)需要HCR。104名符合条件的创伤临床医生中有80名(76%)至少提供了1例HCR。中位院前时间为72分钟(IQR:52-93)。输血阈值和血浆与红细胞比值在各中心之间是一致的。表1显示了预测时的详细预测变量可用性。
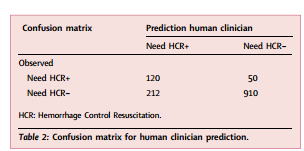
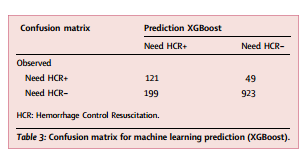
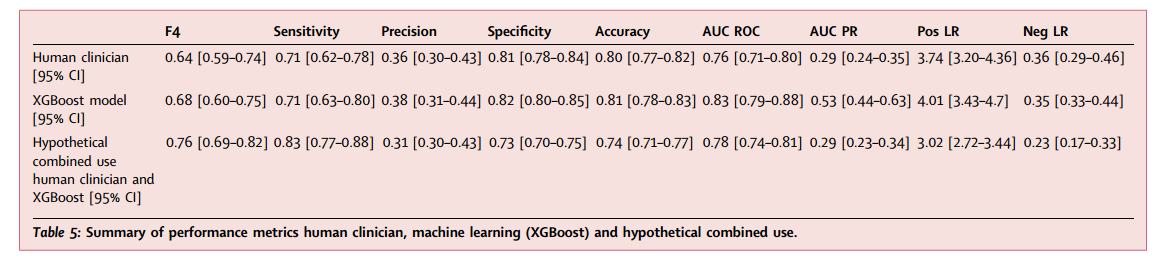
创伤临床医生对HCR需求的预测得出敏感度71%(95%CI:62-78%),特异度81%(95%CI:78-84%),阳性似然比3.74(95%CI:3.20-4.36),阴性似然比0.36 (95%CI:0.29-0.46),精确度36%(95%CI:30-43%),准确度0.80(95% CI: 0.77-0.82),F4分数0.64(95%CI:0.59-0.74)。机器学习模型(XGBoost)的预测得出敏感度71%(95%CI:63-80%),特异度82%(95%CI:80-85%),阳性似然比4.01(95%CI:3.43-4.70),阴性似然比0.35(95%CI:0.33-0.44),F4分数0.68(95%CI:0.60-0.75)。两种方法的灵敏度差异无统计学意义(Z检验,p = 1)。表2和表3展示了创伤团队临床医生和机器学习预测(XGBoost)的混淆矩阵。
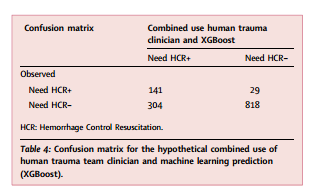
创伤临床医生和机器学习模型的净临床效益计算为0.07。当临床医生和机器学习模型的预测相结合时,来自任何一个来源的阳性预测都被视为阳性,灵敏度增加到83%(95% CI:77-88%),特异性为73%(95% CI:70-75%)。这种联合方法得出的似然比+为3.02(95%CI:2.72-3.44),似然比-为0.23(95%CI:0.17-0.33),联合方法的净临床获益为0.08。实际上,在100名患者的样本中,这相当于使用组合方法正确识别了8名患者而没有伤害,相比之下,创伤临床医生或机器学习模型单独识别了7名患者。
表4和表5总结了创伤临床医生预测、机器学习模型(XGBoost)和假设组合方法的性能指标。
人类创伤临床医生和机器学习模型预测没有产生相同的假阴性病例。具体来说,创伤临床医生预测产生了21个被XGBoost模型正确识别的假阴性病例,而模型遗漏了20个由创伤临床医生检测到的病例。表6列出了两个预测源的预测变量及其在假阴性患者中的分布。在假阴性预测的情况下,创伤临床医生和机器学习模型在变量 “儿茶酚胺使用”和“穿透性创伤”上的分歧最为明显。在创伤临床医生预测的50个假阴性中,儿茶酚胺的使用占12.4%(6/50),而在该模型的81.2个假阴性中,存在18%(49/49)。相反,84%(21/50) 的临床医生衍生的假阴性发生了穿透伤,而机器学习模型的假阴性为28%(14/49)。
在临床医生经验方面,非常缺乏经验的临床医生(<3年执业经验)和经验丰富的临床医生(>9岁)的假阴性率较高(分别为38%和34%,与具有中级经验的人相比(3-9岁)。没有发现白班与夜班或工作日与周末班之间有显著的相关性。参与的中心。人类和机器学习预测之间的一致性为中等,Cohen's kappa系数为0.51(95% CI:0.48-0.55)。未报告智能手机应用程序的故障或技术问题,也未观察到其使用对患者护理或伤害的影响。
五、结论
机器学习模型没有替代医生,但能增强其决策意识,在不干扰临床流程的前提下实现较好的可行性和效益。未来研究应评估该工具对临床工作流、指南依从性及资源使用的影响,并进一步探讨其成本效益与跨系统适用性。


下一篇:评估活体肾切除术后早期供体肾功能恢复作为肾移植后移植失败的预测指标:一项纵向队列和机器学习研究
