
发布时间: 2025-05-29 17:11:40
2025年4月26日,Sangsang Qi等人在《BMC Pregnancy and Childbirth》杂志上发表了一篇题为《Building a machine learning-based risk prediction model for second-trimester miscarriage》的文章。本研究旨在构建一种基于机器学习的风险预测模型,用于准确预测孕妇在妊娠中期(14+0至27+6周)发生流产的风险。
图1 预测模型流程图
研究背景
妊娠中期流产(STM)是常见的不良妊娠结局,占所有流产的2%-3%,但其对患者身心健康的长期影响常被低估。现有研究多聚焦于妊娠早期流产或早产,而妊娠中期流产的预测模型研究较少。传统统计方法在复杂因素分析中存在局限性,机器学习(ML)因其处理非线性关系和特征交互的优势,成为构建预测模型的有力工具。本研究基于临床实际需求,结合炎症标志物、宫颈长度等潜在风险因素,探索建立高精度、可解释的妊娠中期流产预测模型。
数据来源
研究回顾性收集了2020年1月至2023年10月期间在宁波大学妇女儿童医院住院、诊断为“先兆流产且孕周为14+0至27+6周的2006例患者数据。排除标准包括入院时已确诊“难免流产”、严重系统性疾病、胚胎染色体异常及失访病例。数据涵盖30项临床特征,包括年龄、孕周、阴道出血、宫颈长度、白细胞计数(WBC)、C反应蛋白(CRP)等。
研究方法
研究采用分层随机抽样将数据分为训练集(70%)和验证集(30%)。通过Boruta算法筛选关键特征,结合多元逻辑回归进一步确定最终10个预测变量(如宫颈长度、阴道出血、CRP等)。针对数据不平衡问题,使用SMOTE过采样技术平衡正负样本。构建了包括逻辑回归(LR)、支持向量机(SVM)、随机森林(RF)、XGBoost等7种机器学习模型,并基于准确率、召回率、ROC-AUC、PR-AP等指标评估性能。通过SHAP方法解释模型预测逻辑,并开发了在线可视化工具。
结果
研究人群的基线特征
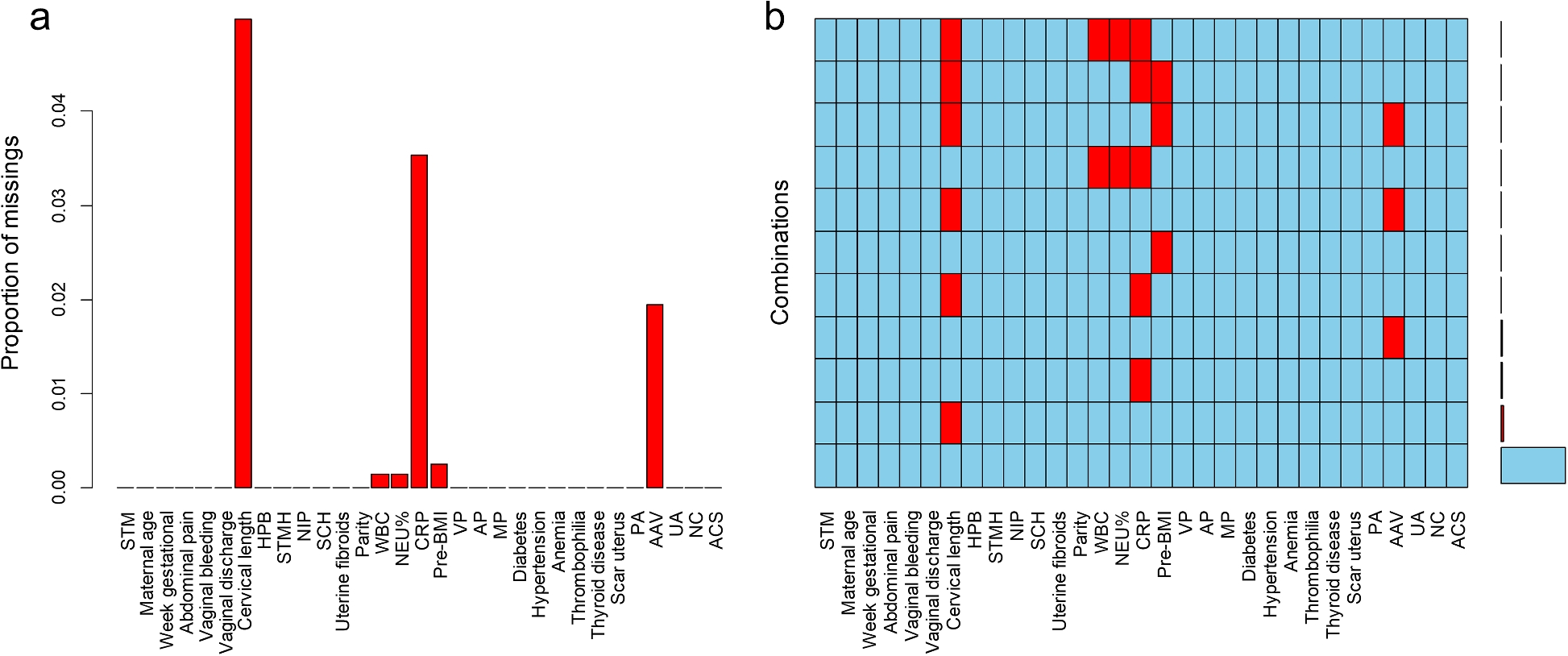
2020年1月至2023年10月,宁波大学附属妇幼医院共收治了2172例妊娠 14+0周至 27+6周被诊断为“先兆流产”的患者。根据排除标准,我们排除了166例患者:其中2例患有精神障碍,153例反复住院,11例因特殊原因自动出院。最终,我们的研究共纳入2006例患者;其中395例(19.69%)患者发生自然流产。作者考虑了30个潜在预测变量进行分析,并统计分析了所有纳入病例中每个因素的缺失值。宫颈长度(4.99%)、CRP(3.54%)、异常羊水量(1.94%)、孕前BMI(0.25%)、白细胞计数(0.15%)、中性粒细胞百分比(0.15%)的缺失数据占个人数据的5%以下,如图2所示。我们使用数值变量的平均值和分类变量的众数来填充缺失值。
图2 缺失值分析
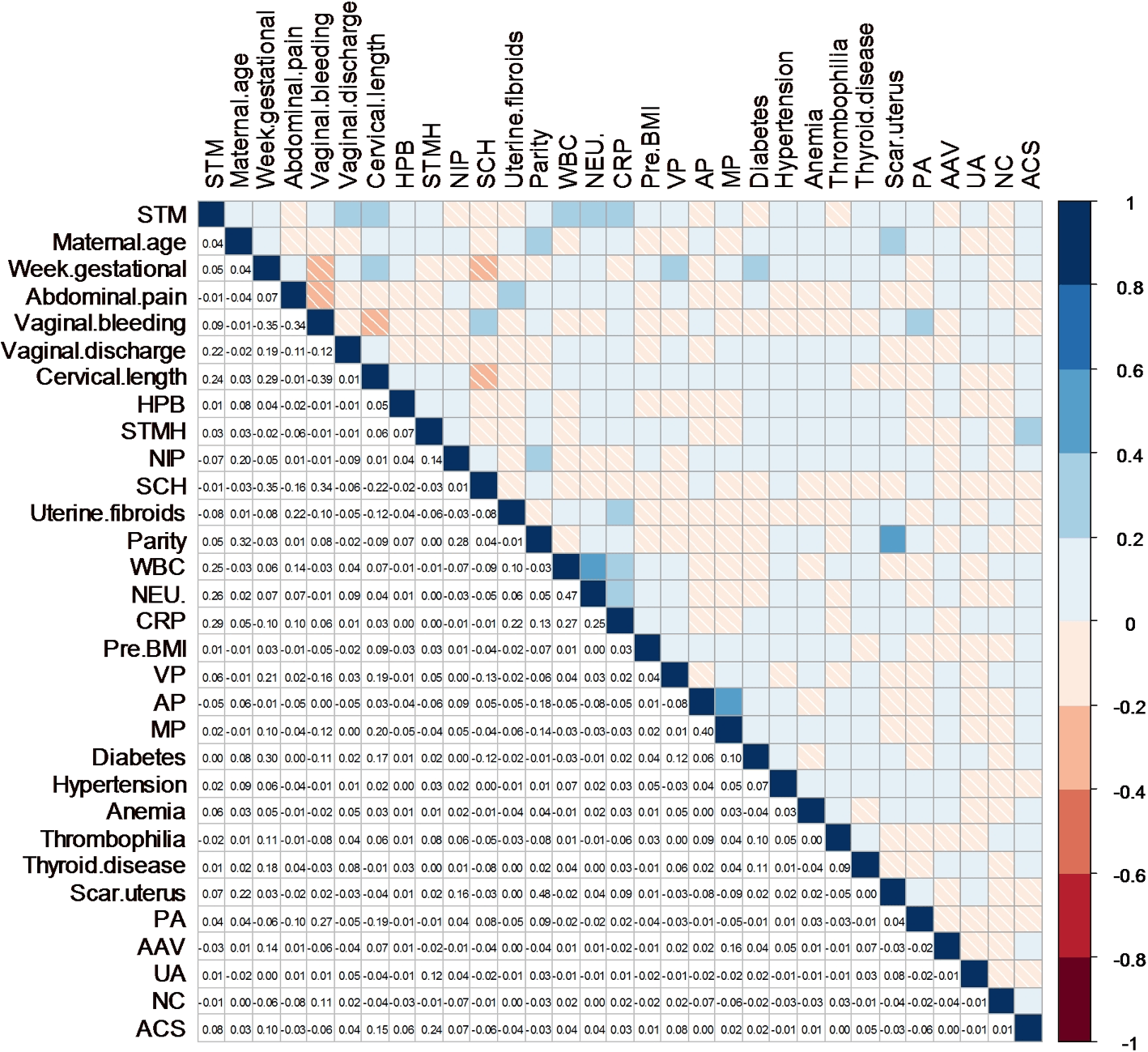
本研究考察了30个可能导致STM的风险变量。为了避免众多特征之间的共线性,创建了相关性热力图来预测STM的风险特征。相关性热力图是一种可视化工具,它以热图的形式显示特征之间的相关系数,并用颜色阴影表示特征之间的相关程度。图3展示了纳入研究中风险特征的相关性分析,Spearman相关系数小于0.6,表明纳入特征之间的相关性较低。
图3 相关性热力图
特征选择
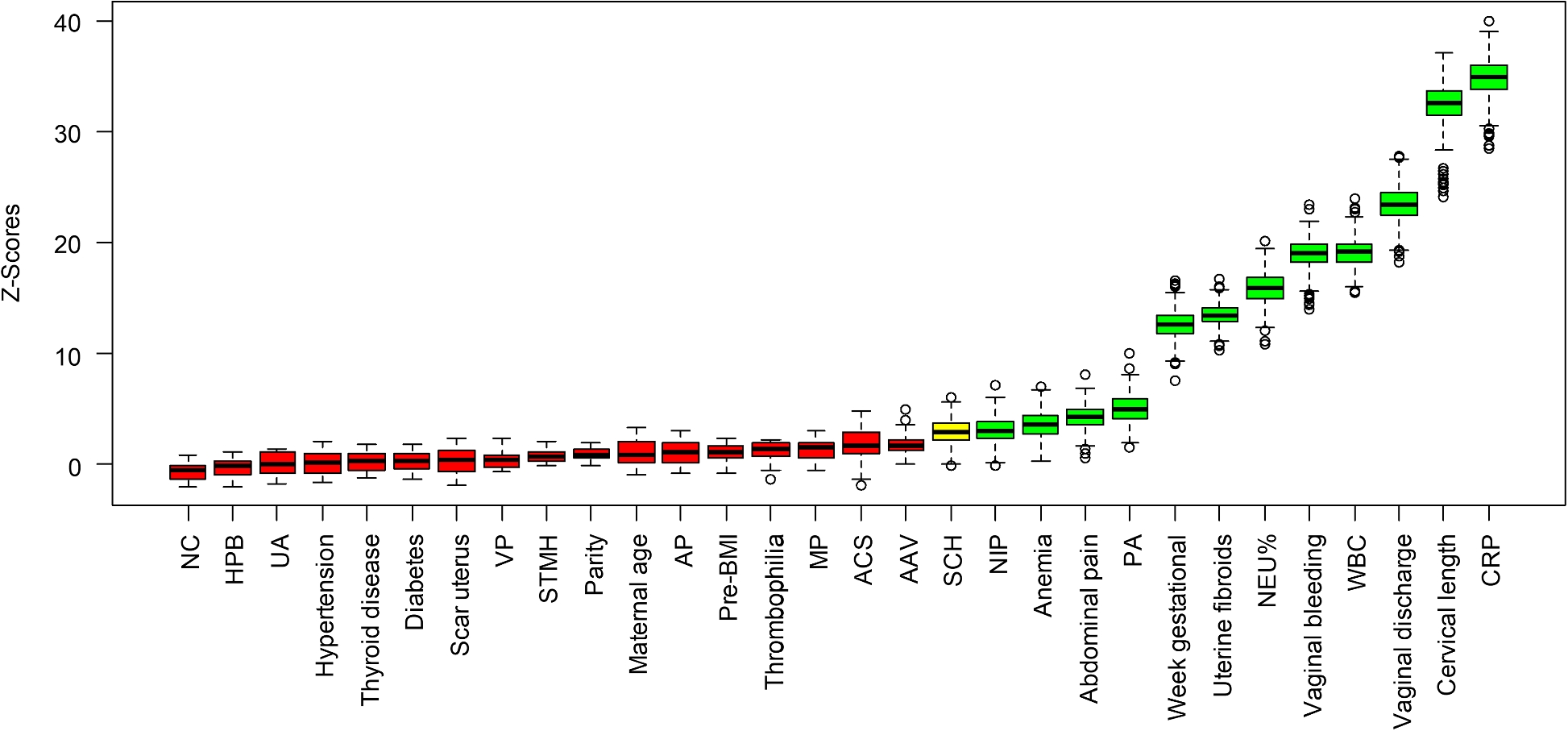
Boruta是一种基于随机森林分类器的特征选择算法。在我们的研究中,Boruta进行了500次迭代,选择结果总结在图4中。以下特征与STM风险相关:孕妇年龄、腹痛、阴道出血、阴道分泌物、宫颈长度、宫内手术次数、绒毛膜下血肿、子宫肌瘤、白细胞、中性粒细胞百分比、CRP、贫血和胎盘异常。
图4 Boruta特征筛选
图5显示了13个特征的多变量分析。选择具有统计学显着差异(P <0.05)的特征作为最终特征。最终理想的10个特征为:腹痛、阴道出血、阴道分泌物、宫颈长度、绒毛膜下血肿、子宫肌瘤、白细胞、中性粒细胞比例、C反应蛋白、胎盘异常。统计结果显示,发生STM的风险为19.69%,明显低于无流产的概率,说明数据样本不平衡。本研究利用SMOTE过采样技术生成少数样本,确保孕中期阳性样本与阴性样本比例为1:1,且数据结构平衡 ,生成SMOTE后数据集。
图5 多因素分析
模型构建与评估
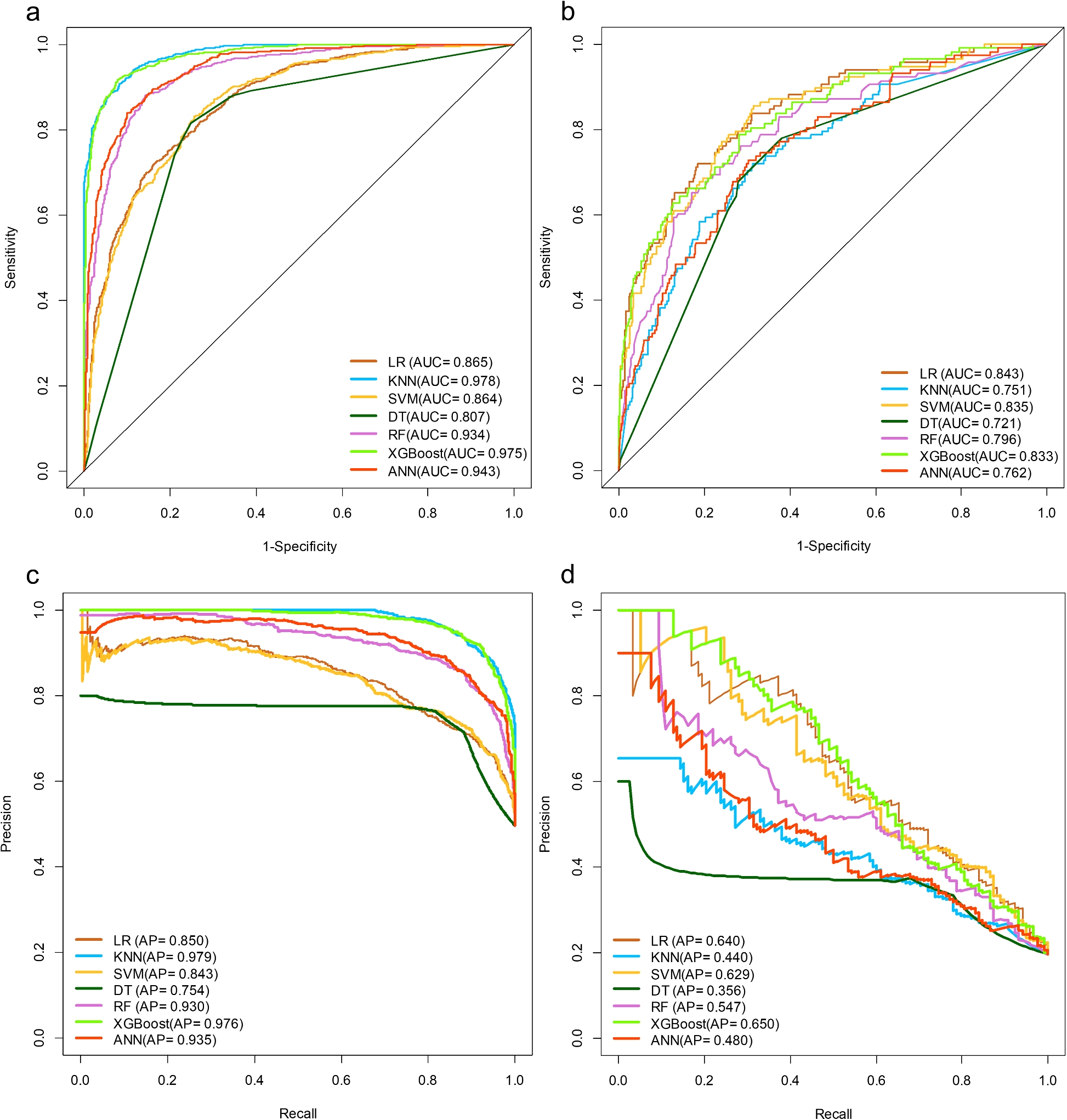
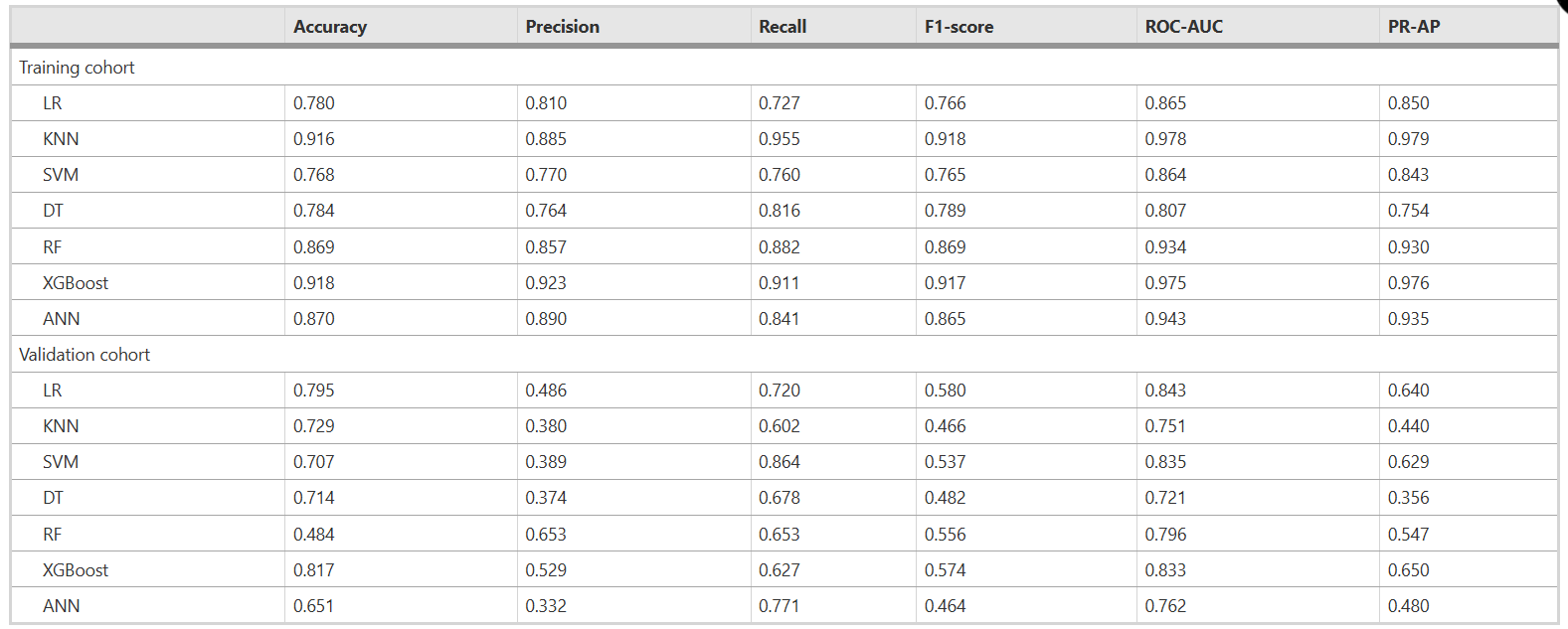
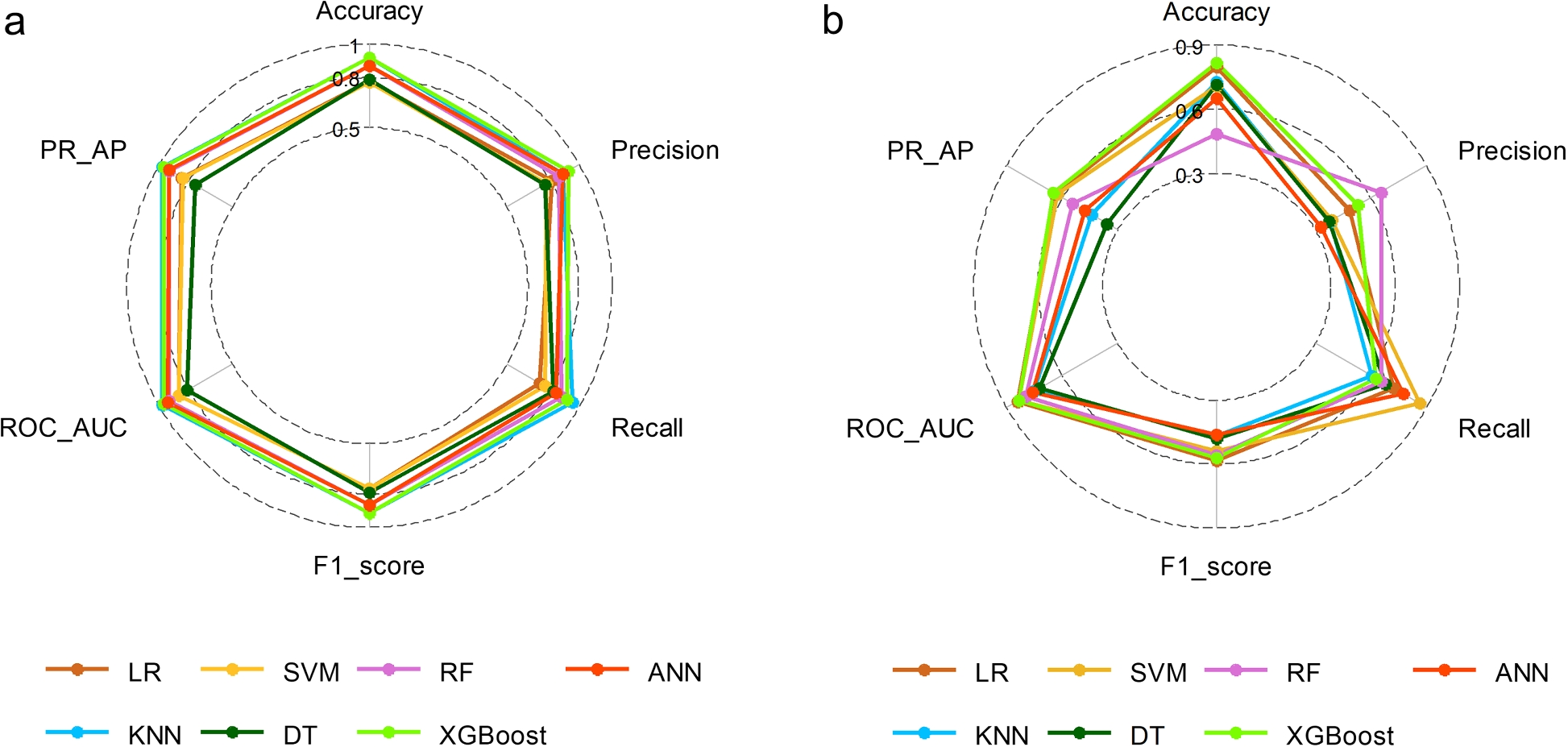
本研究采用了七种不同的机器学习技术建立模型:LR、KNN、SVM、DT、RF、XGBoost和ANN。图6展示了这七种模型在训练队列和验证队列中的ROC-AUC和PR-AP性能。表1比较了准确率、精确率、召回率和F1分数,并使用图7中描绘的雷达图从多个维度比较了每个模型的性能数据,以增强结果的清晰度和视觉吸引力。在七种模型中,有三个模型都表现出较高的预测性能:LR模型(AUC = 0.843)、SVM(AUC = 0.835)和 XGBoost(AUC = 0.833)AUC大于0.8表示预测性能良好。KNN(AUC = 0.751)、DT(AUC = 0.721)、RF(AUC = 0.796)和ANN(AUC = 0.771)模型的预测能力中等。RF模型的精确度最高,为0.653,其次是XGBoost(精确度为 0.529)。但XGBoost的PR和准确度最高,分别为0.650和0.817。
图6 ROC曲线与召回曲线
表1 各模型预测性能比较
图7 机器学习模型性能分析的雷达图
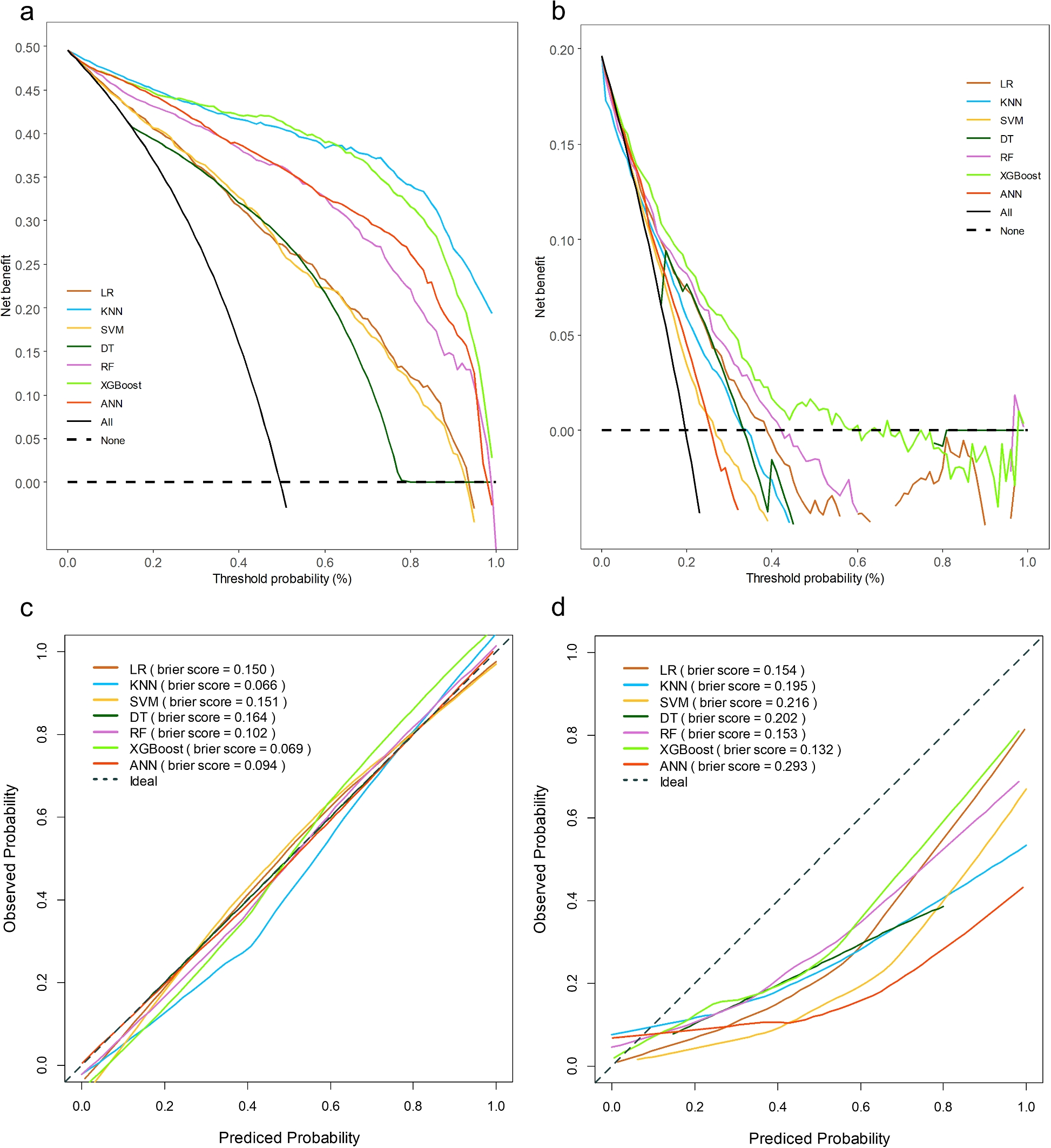
当使用临床决策曲线分析(DCA)评估预测模型的临床有效性时,XGBoost模型在特定范围内获得的净收益大于其他模型(图8),表明XGBoost模型具有良好的临床实用性。校准曲线分析显示,XGBoost模型的表现优于其他模型,其Brier Score最低(验证组中为0.132)。
图8 临床决策曲线和召回曲线
前瞻性验证
对预测模型进行临床评估,前瞻性收集了2024年1月至3月宁波大学附属妇幼保健院符合纳入和排除标准的120例患者资料,其中18例(15.0%)患有 STM。模型准确率为0.858,精确率为0.519,召回率为0.778,F1得分为0.622,ROC-AUC为0.883,PR-AP为0.702,结果如表2所示。
表2 XGBoost的前瞻性验证
SHAP 模型解释
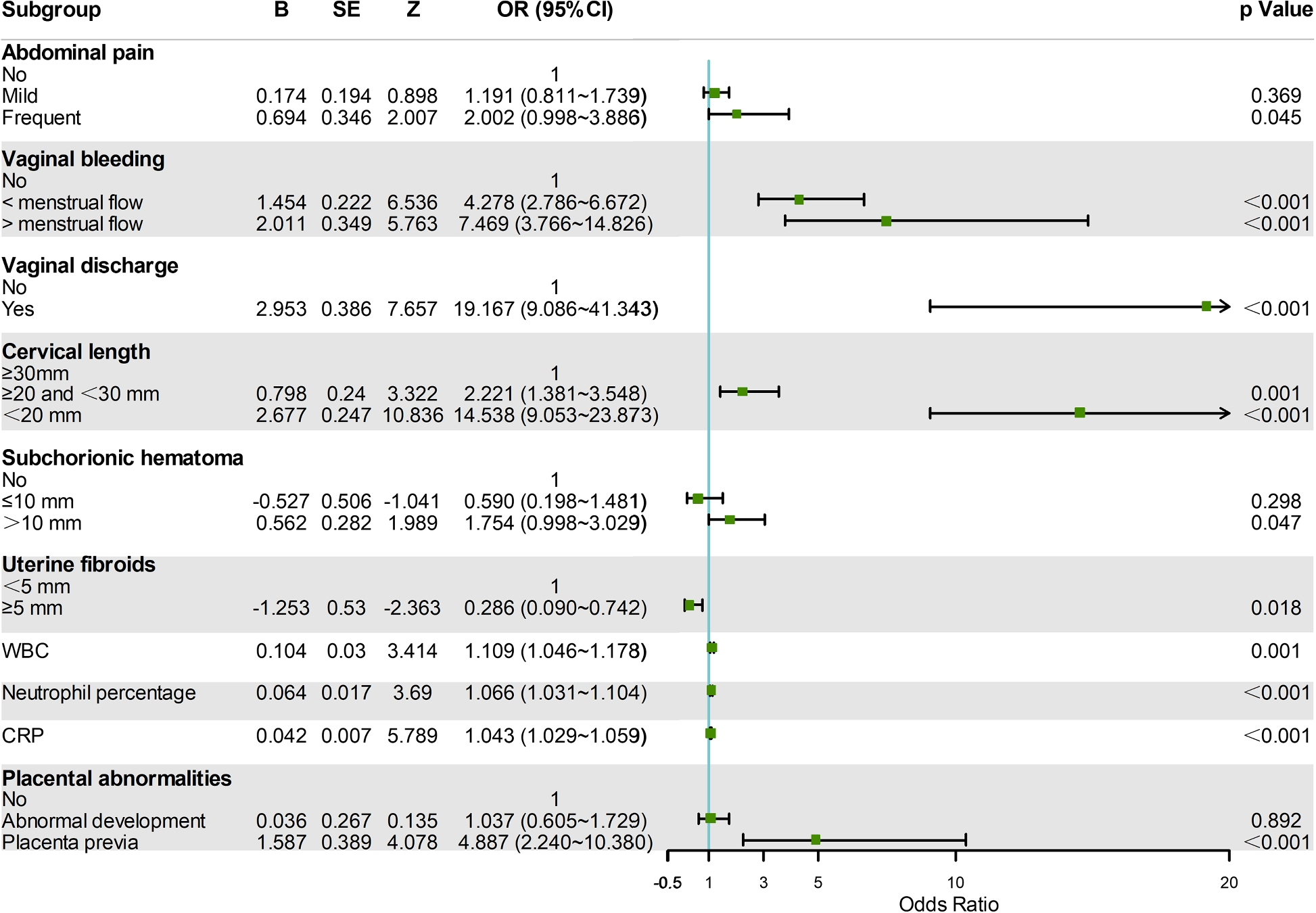
SHAP分析显示,宫颈长度是预测中期流产的最关键因素,其缩短显著增加风险(如长度<20mm时风险升高14.5倍)。其他重要特征依次为C反应蛋白(CRP)、中性粒细胞百分比、阴道出血及阴道分泌物。模型解释表明:宫颈缩短、炎症标志物升高(如CRP>2.27mg/L)、阴道出血等正向驱动流产预测;而宫颈长度正常(如≥30mm)、无出血等特征则降低风险。通过可视化案例,SHAP直观展示了各特征对个体预测结果的贡献方向与强度,为临床决策提供可解释依据。
图9 SHAP可解释性分析
网页应用程序
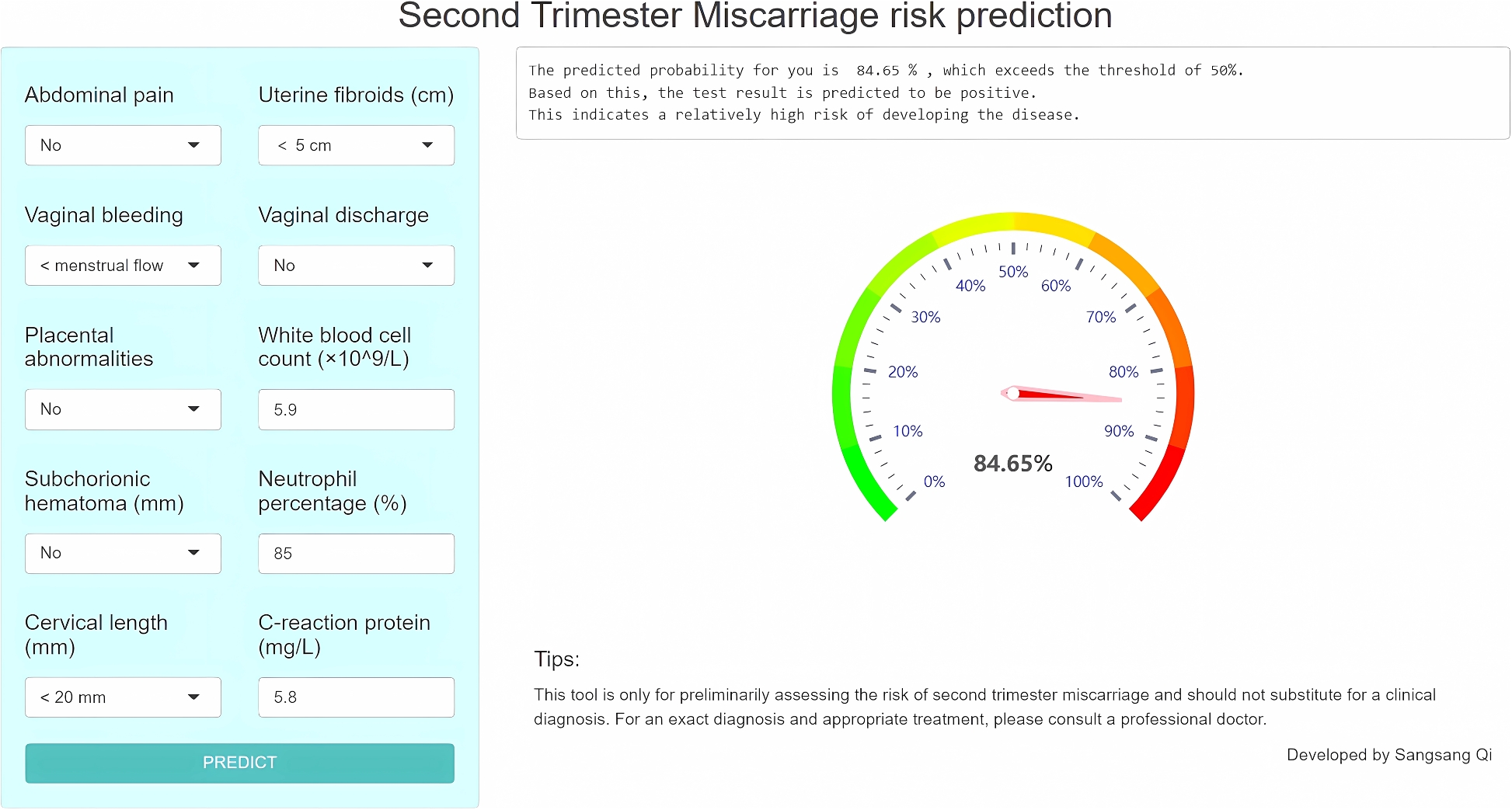
此外,还为临床医生构建了一个基于网络的工具来使用所提出的模型(网址为 https://qisangsang.shinyapps.io/STMRISK/)(图10)。
图10 网页计算器
结论
研本研究成功构建了基于XGBoost算法的中期流产风险预测模型,其性能优于传统统计方法,并通过SHAP实现可视化解释。模型整合了易获取的临床指标,为早期识别高危孕妇提供了实用工具。




上一篇:机器学习算法用于预测早发心肌梗死患者中射血分数保留型心力衰竭
