2025年5月7日,Jing-Xian Wang等人在《Front Cardiovasc Med》杂志上发表了一篇题为《Machine learning algorithms to predict heart failure with preserved ejection fraction among patients with premature myocardial infarction》的文章。 早发性心肌梗死(PMI)患者射血分数保留的心力衰竭(HFpEF)是影响长期预后的关键因素。本研究旨在开发一种基于机器学习算法的模型,该模型可以及早快速预测PMI患者发生院内HFpEF的风险。
HFpEF在急性心肌梗死(AMI)患者中占比逐年上升,尤其在年轻人群中预后较差,但其预测模型研究仍存在空白。因此本研究聚焦于比较不同机器学习模型的性能,筛选关键预测因子,并构建可解释的临床决策支持工具,从而为高风险患者的个体化干预提供依据,降低HFpEF发病率并改善长期预后。
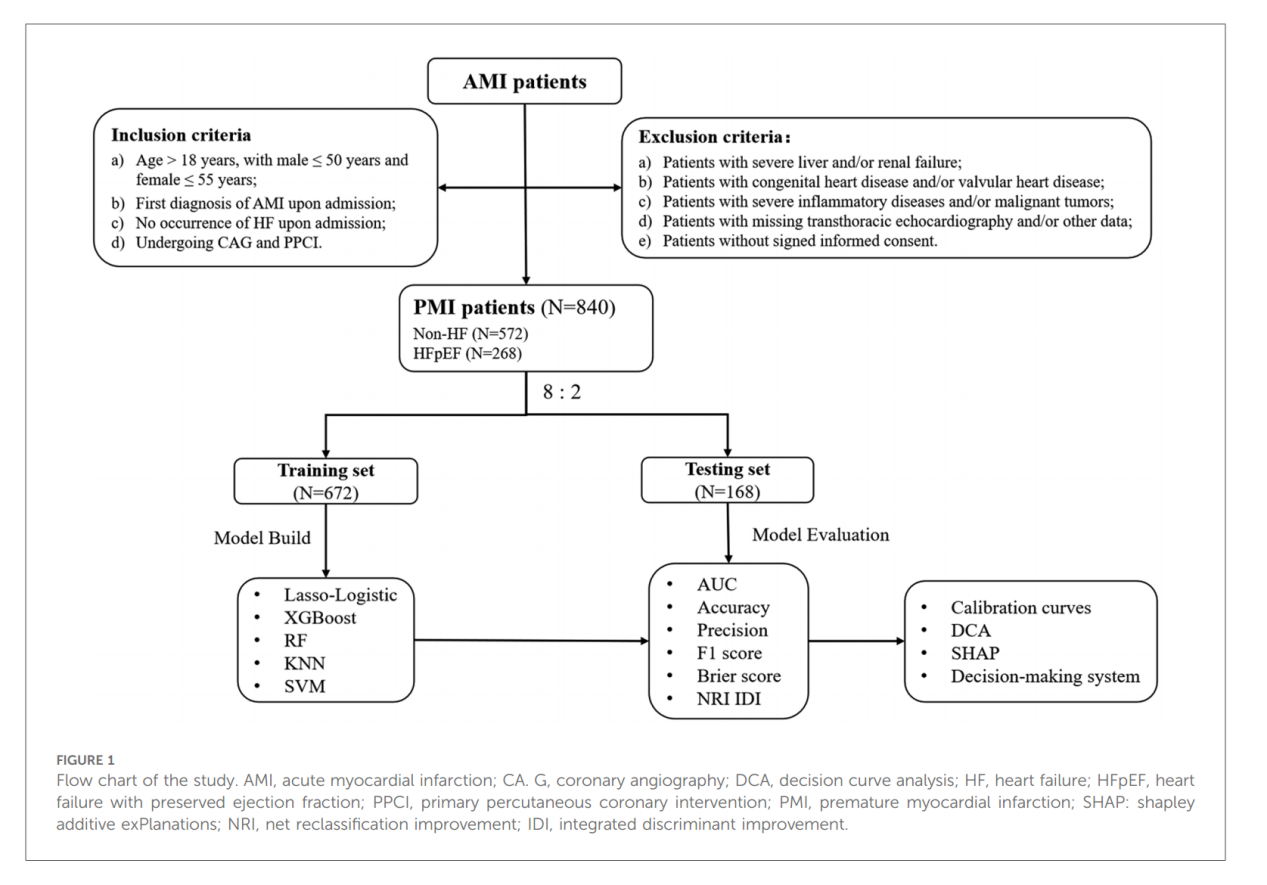
本研究数据来源于2017年1月至2022年12月天津胸科医院的前瞻性单中心队列,纳入840例AMI的患者。纳入标准包括:符合PMI年龄标准(年龄>18岁,且男性≤50岁或女性≤55岁);首次诊断为AMI;入院时无心力衰竭、接受冠状动脉造影(CAG)及直接经皮冠状动脉介入治疗(PPCI)。排除严重肝肾功能衰竭、先天性或瓣膜性心脏病、严重炎症性疾病、恶性肿瘤、关键检查数据缺失及未签署知情同意书的病例。
收集数据包括人口学特征即年龄、性别、BMI、吸烟与饮酒史、冠心病家族史(CAD)、既往病史、AMI类型);入院生命体征;实验室检查、冠状动脉造影(CAG)及经胸超声心动图(TTE)参数;实验室指标如炎症比值CLR(C反应蛋白与淋巴细胞比值)和MLR(单核细胞与淋巴细胞比值)、冠脉造影结果(含SYNTAX评分)、超声心动图参数及用药信息。所有数据均通过标准化电子病历系统采集以确保一致性。研究流程详见图1。
本研究基于Riley等人提出的pmsampsize准则确定最小样本量为298例。数据缺失率低于5%的变量采用中位数填补连续变量缺失值,分类变量使用多重插补。数据集按8:2比例随机分为训练集(80%)和测试集(20%),训练集内采用五折交叉验证。除年龄经最小-最大标准化外,其余连续变量均按临床参考范围(如BMI≥24 kg/m²)、指南或中位数如总胆汁酸(TBA)、CLR、MLR转换为分类变量。针对HFpEF样本量不足问题,采用SMOTE技术平衡数据(k=5,过采样比=1)。构建五种机器学习模型,包括套索逻辑回归(Lasso-Logistic)、极限梯度提升(XGBoost)、随机森林(RF)、K近邻(KNN)、支持向量机(SVM)模型预测院内HFpEF的发生。通过方差膨胀因子(VIF>10)排除多重共线性变量后,Lasso回归筛选出12个关键预测因子并构建逻辑模型;其余模型基于全变量训练后,选取特征重要性排名前10的变量重新建模。模型优化采用自动调参策略,结合五折交叉验证评估泛化性能,最终通过测试集计算AUC、准确率、F1分数及Brier分数进行验证。使用净重新分类改进指数(NRI)和综合判别改进指数(IDI)量化模型预测能力的提升,并基于性能对比选定最优模型。模型解释采用SHAP值可视化变量贡献度,校准曲线评估预测概率与实际概率的一致性,决策曲线分析(DCA)量化不同阈值下的临床净获益。
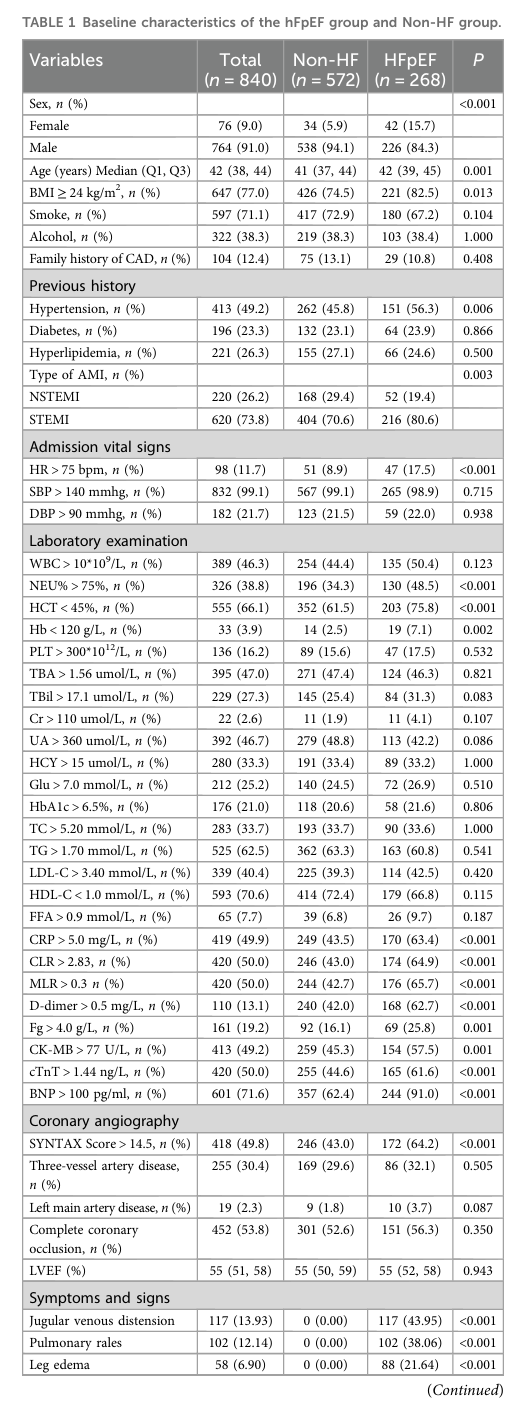
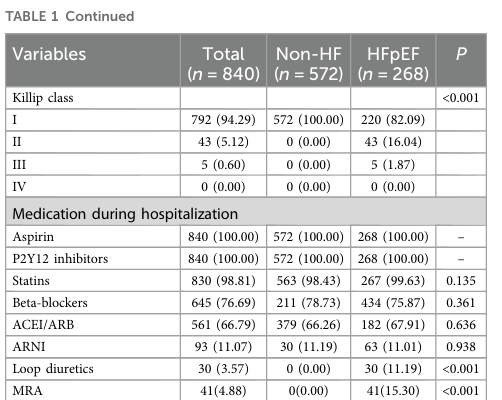
研究人群基线特征如表1所示,共纳入840例患者(HFpEF组268例,非HF组572例),中位年龄42[38-44]岁,男性占91.0%。组间比较显示,HFpEF组女性比例显著高于非HF组(15.7% vs. 5.9%,P<0.001),年龄更大(42[39-45] vs. 41[37-44]岁,P=0.001),肥胖(BMI≥24 kg/m²:82.5% vs. 74.5%,P=0.013)和高血压(56.3% vs. 45.8%,P=0.006)比例更高。实验室指标方面,HFpEF组炎症标志物(CRP>5.0 mg/L:63.4% vs. 43.5%;MLR>0.3:65.7% vs. 42.7%,均P<0.001)及脑钠肽(BNP)>100 pg/ml比例(91.0% vs. 62.4%,P<0.001)显著升高。冠脉造影显示HFpEF组SYNTAX评分>14.5的比例更高(64.2% vs. 43.0%,P<0.001),提示更严重的冠脉病变。综上,HFpEF患者具有年龄较大、合并症负担更重、心血管功能障碍更显著的特征。训练集与测试集的基线特征及连续变量描述性统计分别见补充表S2和S3。
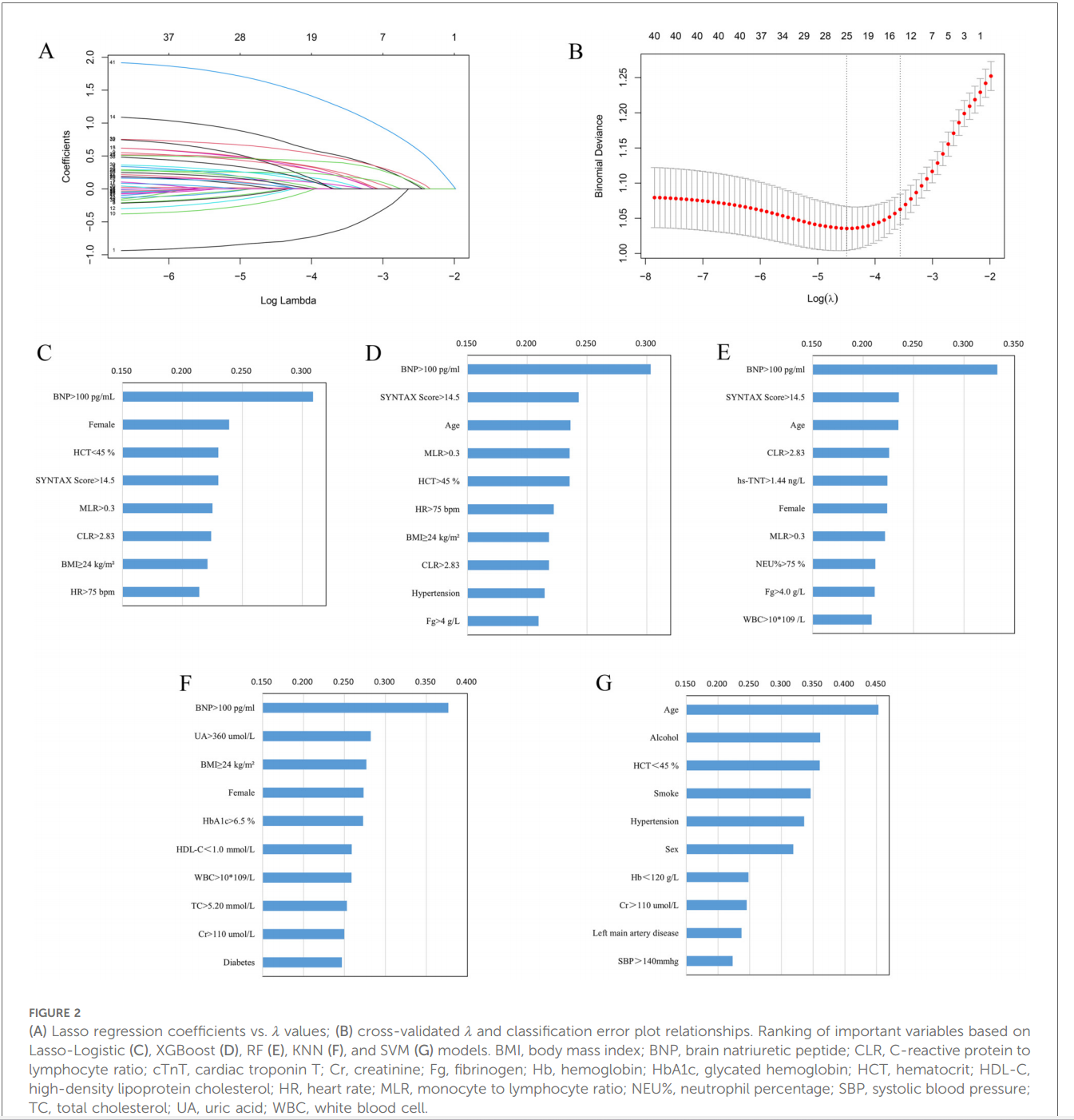
研究将840例患者按8:2比例随机划分为训练集(672例)和测试集(168例),所有预测变量的方差膨胀因子(VIF)均<5,表明多重共线性问题不显著。基于Lasso回归的变量筛选(图2A-B)从全变量集中识别出12个关键预测因子,包括女性、高血压、STEMI、BMI≥24 kg/m²、SYNTAX评分>14.5、入院心率(HR)>75次/分、中性粒细胞百分比(NEU%)>75%、红细胞压积(HCT)<45%、心肌肌钙蛋白T(cTnT)>1.44 ng/L、MLR>0.3、CLR>2.83及BNP>100 pg/ml。经多因素Logistic回归进一步筛选后,最终模型保留8个变量:女性、BMI≥24 kg/m²、SYNTAX评分>14.5、HR>75次/分、HCT<45%、MLR>0.3、CLR>2.83及BNP>100 pg/ml。RF、XGBoost、KNN和SVM模型经全变量训练后,基于特征重要性排名选取前10个变量重新建模。各模型的特征重要性排序分别展示于图2C-G中,其中XGBoost模型的关键变量包括BNP水平、SYNTAX评分、年龄、炎症比值等(如图2D)。
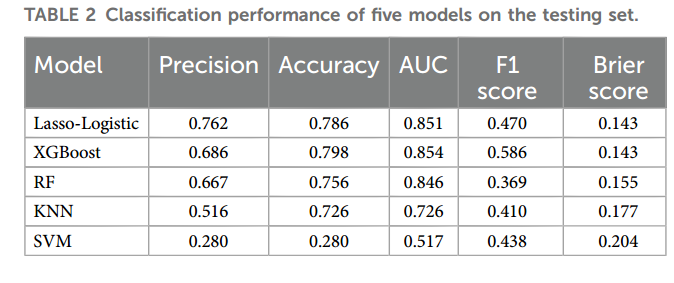
各模型在测试集的分类性能比较如表2及图3A-B所示。五种机器学习模型的AUC范围为0.517(SVM)至0.854(XGBoost),其中XGBoost的AUC、准确率(0.798)及F1分数(0.586)均为最优,Brier分数(0.143)与Lasso-Logistic相当。雷达图(图3B)综合显示XGBoost在多数指标上表现突出。补充图S1表明,SMOTE技术有效平衡了训练集类别分布,提升XGBoost与KNN的F1分数及AUC,但SVM性能未改善。
通过净重新分类改进指数(NRI)和综合判别改进指数(IDI)分析,XGBoost相比其他模型预测能力显著更优(均P<0.05)。例如,与Lasso-Logistic相比,NRI=0.149(95%CI:0.008-0.290),IDI=0.049(95%CI:0.008-0.091);与SVM相比,NRI=0.428(95%CI:0.277-0.579),IDI=0.227(95%CI:0.175-0.279)(补充表S5)。校准曲线显示XGBoost预测概率与实际概率高度一致(图3C-D),决策曲线分析(图3E-F)证实其在广泛阈值范围内具有临床净获益。综上,XGBoost因综合性能最优被选为最终模型。
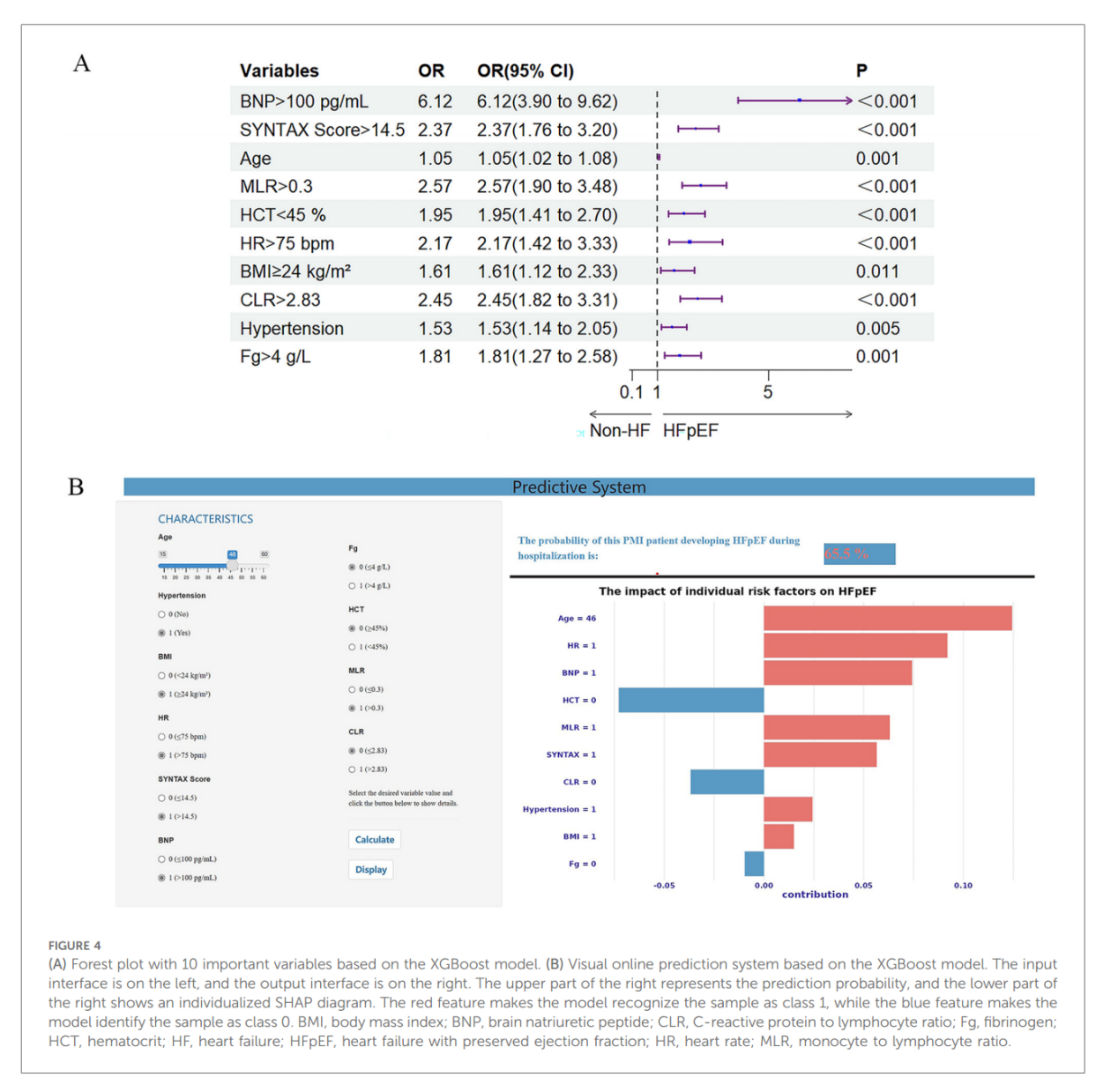
XGBoost模型变量的重要性排序显示BNP >100 pg/ml是影响PMI患者院内HFpEF发生的最重要特征。此外,SYNTAX评分> 14.5、年龄、MLR >0.3、HCT <45%、HR >75 bpm、身体质量指数≥24 kg/m2、CLR >2.83、高血压、Fg ≥4 g/L也是预测HFpEF的重要变量(图2D)。图4A和补充表S6显示,上述变量是PMI患者院内HFpEF的风险因素。
视觉预测系统包括用于输入患者变量(例如,年龄、高血压状态)的输入界面(左)和显示预测概率(上)和解释模型决策的个性化SHAP图(下)的输出界面(右)。在图4B中,系统根据临床输入预测PMI患者发生HFpEF的概率为65.5%。该系统向公众开放https://hfpefpmi.shinyapps.io/apppredict/.
基于XGBoost算法建立的可解释预测模型可以准确预测PMI患者的院内HFpEF风险,该模型有望通过为PMI患者提供及时、优先和精确的干预措施来帮助临床医生做出决策,最终降低HFpEF的发生率并改善长期预后。
上一篇:05.19-05.25 临床预测模型研究顶刊快报
下一篇:构建基于机器学习的孕中期流产风险预测模型