
发布时间: 2025-01-08 13:55:47
2024年12月21日,Fleur S A Wallis等人在《EBioMedicine》杂志上发表了一篇题为《M&M: an RNA-seq based pan-cancer classifier for paediatric tumours》的文章。该文献旨在通过RNA测序数据对52种不同的儿科肿瘤类型及其96个亚型进行分类,特别强调了包含罕见肿瘤类型的分类能力。
一、研究背景
在儿科肿瘤学中,正确诊断多种罕见的肿瘤类型是一项困难但至关重要的过程。传统上,诊断依赖于疾病的组织学和形态学特征。然而,随着基因组范围分析技术(如RNA测序)的进步,现在可以开发出分子分类工具来辅助诊断。
二、数据来源
该文献的数据来源主要来自荷兰乌特勒支的玛西玛公主儿科肿瘤中心(PMC),这是一家专注于儿童肿瘤研究和治疗的国家级医院。从2018年12月1日至2022年6月1日期间,研究人员收集了新鲜冷冻组织样本及液体活检样本,并通过PMC生物库获得了患者的知情同意。最终,构建了一个包含1256个样本的泛癌种参考队列,这些样本涵盖了52种不同的肿瘤类型、96个亚型以及5种非肿瘤组织。此外,为了验证两个分类器Minority和Majority(M&M)的性能,还使用了一个独立的测试队列由美国国家卫生研究院下属的国家人类基因组研究发起的项目,该队列包括471个样本,来源于442名患者,代表39种肿瘤类型、70个亚型和4种非肿瘤组织。值得注意的是,视网膜母细胞瘤患者由于在阿姆斯特丹大学医学中心接受治疗,因此未包含在PMC的参考队列中。
三、研究方法
该文献的统计方法与设计采用了多阶段的机器学习流程来构建一个强大的儿科肿瘤分类器。首先,通过对训练队列使用方差分析统计量进行特征选择,确定了转录本中差异表达最显著的1000个作为初步特征集。随后,利用加权随机森林算法进一步减少特征数量至300个,这些特征是根据它们对模型准确性的影响程度来挑选的。为了处理类别不平衡问题,研究者对数据进行了下采样,确保每个肿瘤亚型至少有一个样本,并且在Minority分类器中限制为最多三个样本,在Majority分类器中则扩展到最多五十个样本。接着,分别采用加权k近邻算法和加权随机森林算法构建了Minority和Majority两个独立的分类器,其中加权k近邻通过留一法交叉验证优化邻居数,并考虑到了类别的权重以提高罕见类别的识别能力。最后,通过集成分类的方法,将两个分类器的概率得分结合起来,计算出综合概率得分,以此来衡量M&M对分类结果的信心度,并最终确定每个样本的最佳分类标签。整个过程中还应用了十折分层交叉验证来评估模型的稳定性和泛化能力。
四、结果
1.参考队列和独立测试队列
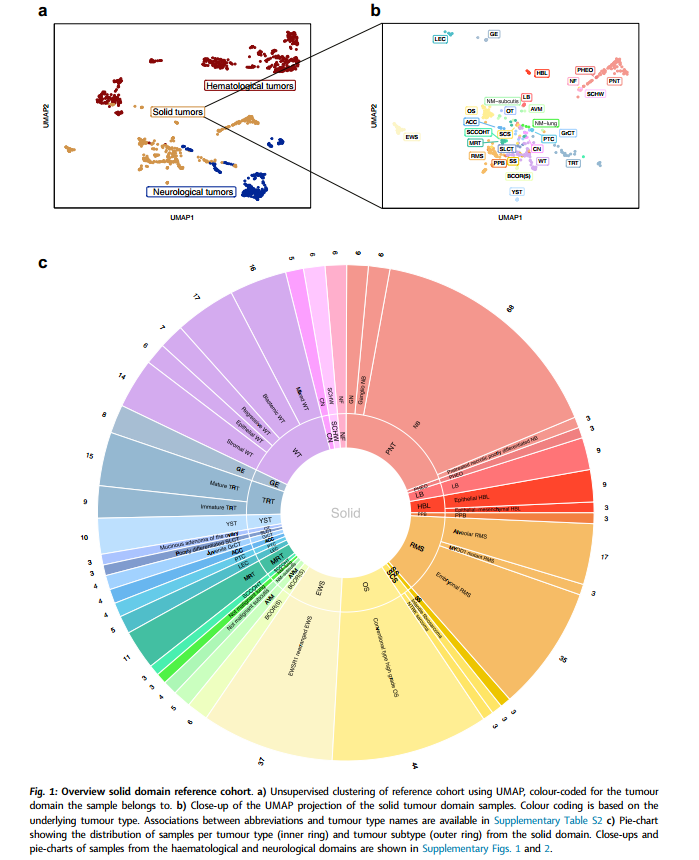
通过图1展示了M&M在固体肿瘤域参考队列中的无监督聚类情况(图1a),UMAP投影显示了不同肿瘤类型的分布(图1b),饼图则呈现了各类型和亚型的样本比例(图1c)。这些可视化结果表明M&M能够有效地区分不同类型的肿瘤样本,并且提供了对训练数据集结构的理解。此外,M&M在内部参考队列中实现了99%的精确度和76%的召回率,而在外部验证队列中,其表现同样优异,达到了98%的精确度和77%的召回率。
2.M&M算法的性能
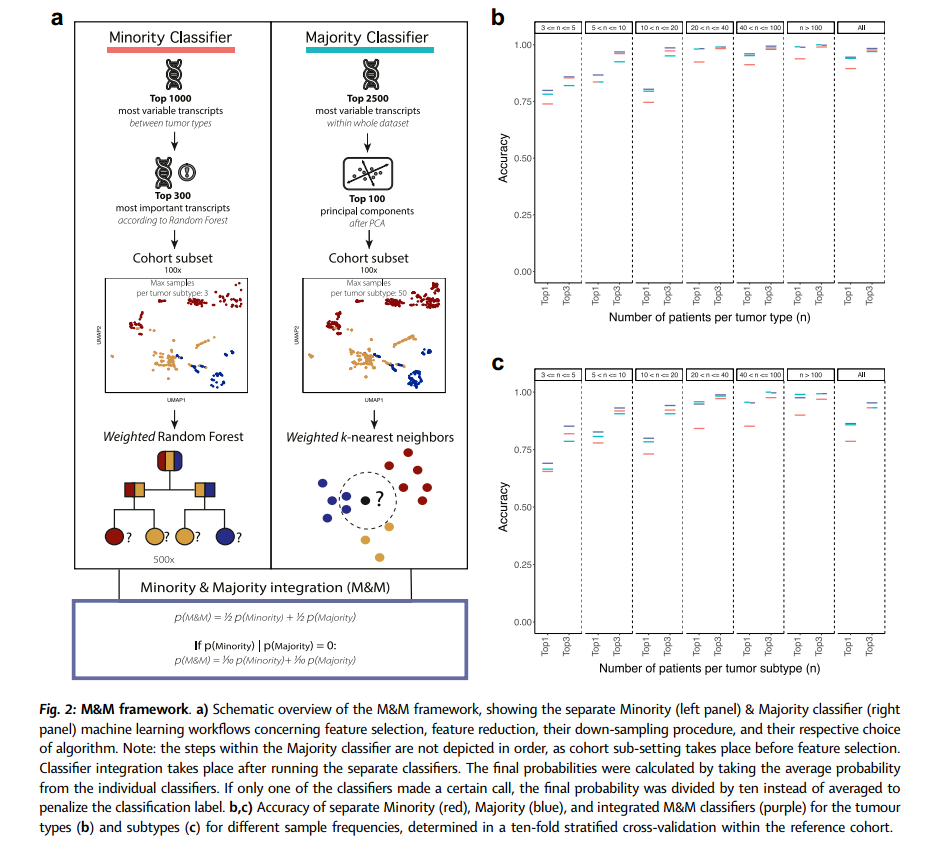
在机器学习中,多数类别偏见使得识别不常见肿瘤(亚)类型尤为困难。为此,我们创建了两个分类器:专注于罕见肿瘤(亚)类型的Minority分类器和针对常见肿瘤的Majority分类器。两者通过相同的四个步骤开发——特征选择、特征减少、下采样和分类,但步骤顺序和方法不同,以实现特定的分类重点(图2a)。分类在肿瘤亚型级别进行,从中推导出肿瘤类型。在常见肿瘤(亚)类型中,Majority分类器在最高排名的标签中表现更好,从20个样本开始趋于饱和。对于概率得分较低的分类,考虑前三个最高排名的标签时,Minority分类器更频繁地包含罕见肿瘤(亚)类型的正确标签(图2b和2c)。
3.分类性能评估
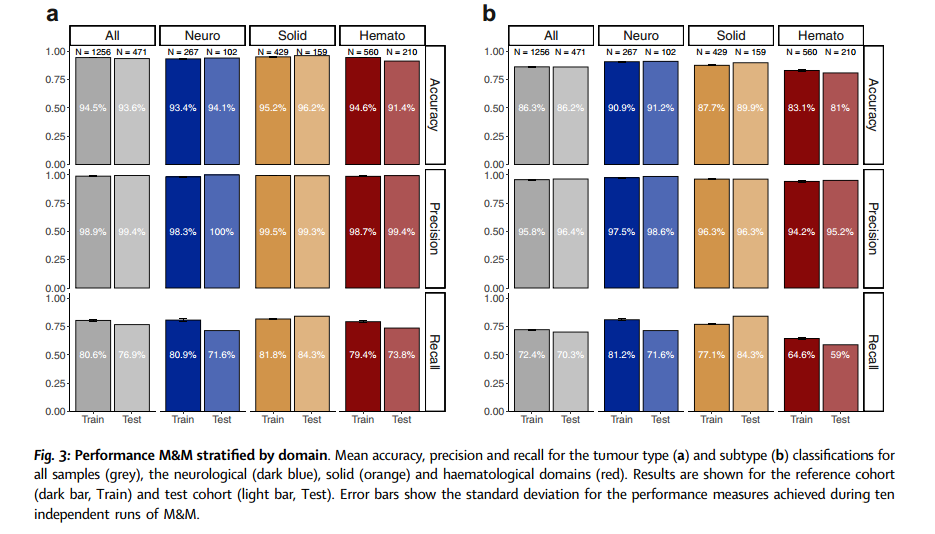
在测试队列中,来自98名独特患者的18个样本(占19%)代表了参考队列中未涵盖的肿瘤亚型。其中,92个样本(占84%)未能获得高置信度分类(即无法分类),展示了M&M识别与算法中所有可用肿瘤类型不符样本的能力。剩余的17个样本中,9个被自信地分类为同一主要肿瘤类型下的不同亚型(8%),而4个是基于组织信号进行分类(4%)。所有没有匹配诊断的样本被排除在外,最终形成了包含471个样本的测试队列。在这一测试队列中,M&M实现了99.4%的肿瘤类型分类精确度,高于参考队列的98.9%(图3a)。对于肿瘤亚型分类,M&M在测试队列中的精确度为96.4%,略高于参考队列的95.8%(图3b)。这些结果表明,M&M在不同领域中表现出一致的高性能,进一步证明了其稳健性。
4.罕见肿瘤类型的分类表现
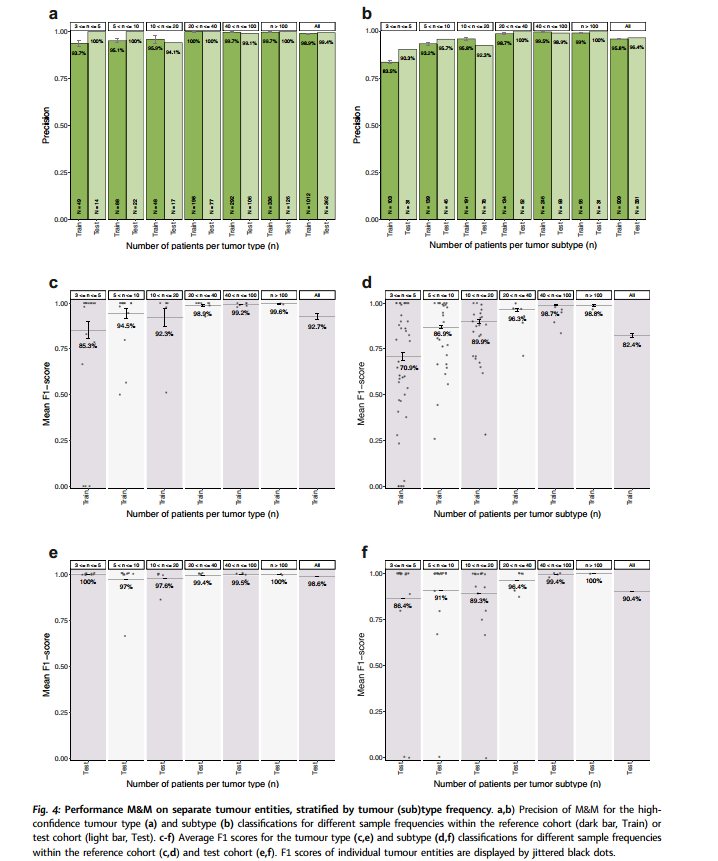
为了使分类结果具有一定的泛化能力,肿瘤类型和亚型根据其在参考队列中的频率进行了分组。基于这些子集,结果显示M&M能够准确分类儿科人群中罕见和常见肿瘤类型(图4a、b),对于罕见肿瘤(3–5个样本)的最小精确度为93.7%,而对于超过100个样本的肿瘤类型的精确度为99%。召回率对于罕见肿瘤类型较低,但仍有68%的样本被自信地分类。M&M在肿瘤类型分类中展示了高平均F1分数(约0.93)(图4c~f),表明个体肿瘤类型可以被准确分类,并且标签在不同类别之间具有区分性。罕见肿瘤类型的平均F1分数较低。如预期,肿瘤亚型分类的整体精确度和F1分数低于肿瘤类型分类,低频亚型的分数最低。具体来说,参考队列中包含3–5个样本的多个亚型在M&M中显得定义不明确(F1 < 0.25)。尽管如此,这些罕见亚型再次表现出较低的召回率,最终精确度约为84%。
5.分类一致性与样本类型无关性
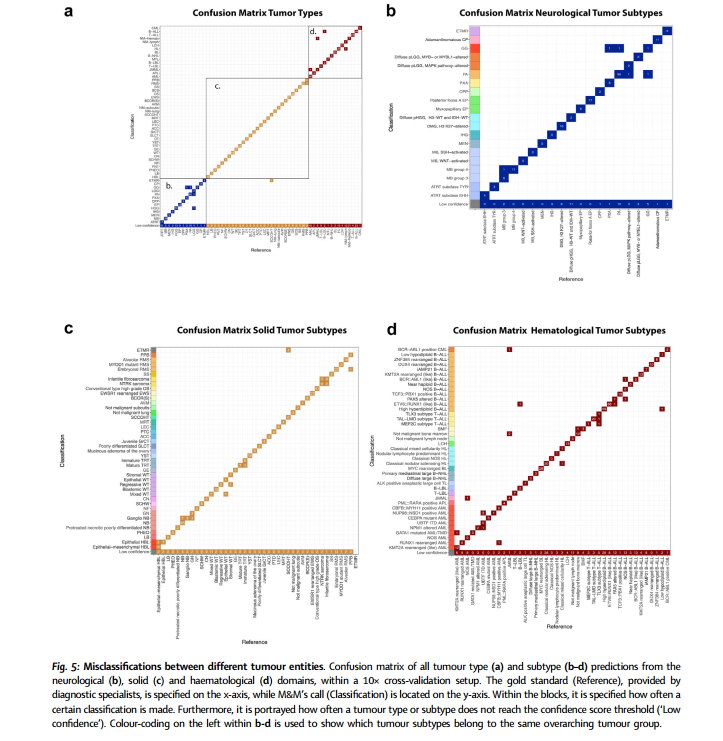
在参考队列的高置信度分类中,M&M总共只有34例肿瘤亚型被错误分类,这些误分类事件并不重复出现,也不依赖于特定样本类型。这表明M&M的错误率很低,且误分类是随机发生的,体现了算法的稳定性和可靠性(图5a)。大多数误分类仅发生一次,并且局限于其所属的原始领域。唯一的一次跨领域误分类发生在卵巢小细胞癌高钙血症型和具有多层菊形团的胚胎瘤之间,这两种均为原始胚胎瘤。此外,肿瘤亚型误分类在所有三个领域的主要肿瘤类型中更为频繁(图5b~d)。
6.不同样本类型的适应性
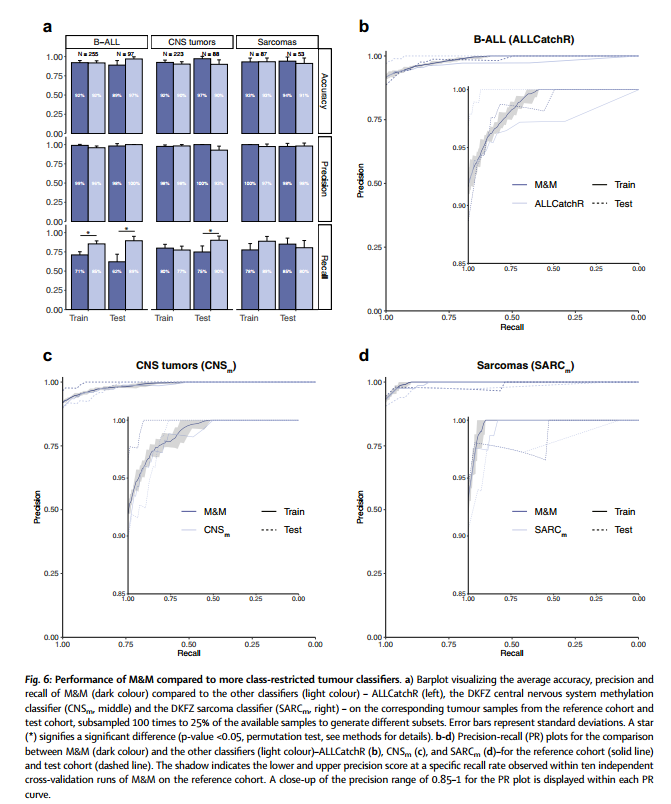
为了确保比较的稳健性,通过下采样生成了100个不同的数据子集,每个子集包含25%的可用样本。随后,从这些子集的性能中计算了平均准确率、精确度和召回率,并给出了标准偏差。结果显示,M&M的准确率和精确度与这些分类器相当(图6a)。为进一步评估分类器的性能,研究生成了精确率-召回率曲线。对于M&M,将十次分类器运行的结果合并,生成每个召回率下的最小、平均和最大精确率(图6c~d)。
7.外部验证数据集的表现
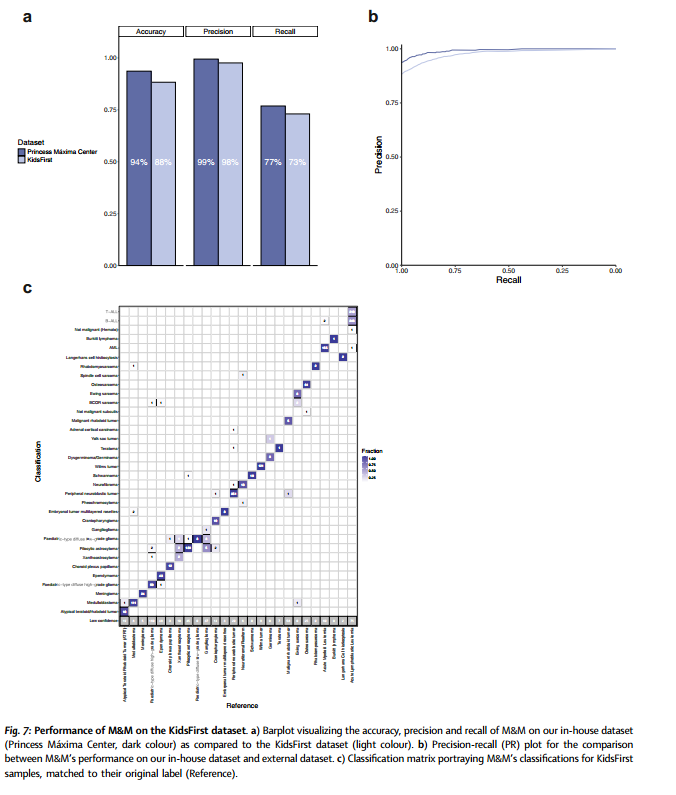
M&M在外部数据集上的验证显示了其出色的泛化能力和稳定性,达到了98.3%的肿瘤类型分类精确度和81.8%的肿瘤亚型分类精确度,证明了其在不同数据源上的可靠性能。尽管在PMC数据集上表现略优(图7a),M&M在外部队列中对于高置信度分类仍能达到98%的精确度(占样本的73%),仅略低于PMC队列的表现(精确度99%,召回率77%)。主要的误分类集中在低概率得分的样本中(图7b),某些肿瘤类型的低置信度分类比例较高(图7c),这可能归因于批次效应和技术变异导致的RNA转录本变化,使得这些样本表现出多种肿瘤类型的特征。
五、总结
M&M是目前最全面的儿科肿瘤特异性分类器,覆盖了整个儿科肿瘤领域,包括29种额外的肿瘤类型和55个亚型。它不仅适用于新鲜冷冻组织,还初步表明可用于RNA测序数据。M&M简化了用户的工作流程,只需提供RNA测序数据和一个分类器即可完成分类任务。
上一篇:免疫球蛋白预防小儿急性淋巴细胞白血病发热住院的效果:多中心试验结果
