
发布时间: 2025-05-08 14:29:42
2025年4月26日,Yue Zhang等人在《eBioMedicine》杂志上发表了一篇题为《Prediction of acute and chronic kidney diseases during the post-covid-19 pandemic with machine learning models: utilizing national electronic health records in the US》的文章。本研究旨在旨在利用大型电子健康记录(EHR)和机器学习(ML)算法预测疫情后急性肾损伤(AKI)和慢性肾脏疾病(CKD)的发病率,评估将COVID-19感染史作为预测指标的必要性,并开发一个可供临床使用的实用网页应用程序。
■
研究背景
■
CKD和AKI是美国成人中的常见疾病,但早期诊断困难,且COVID-19感染已被证实与肾脏并发症风险增加相关。现有机器学习模型多基于小规模临床数据或未包含COVID-19相关变量,且缺乏针对后疫情时代普通人群的大规模研究。因此,本研究通过整合COVID-19感染次数、住院史、实验室指标(如估计肾小球滤过率(eGFR)、血尿素氮(BUN))等69个基线变量,填补了这一空白,并强调临床实用性。
■
数据来源
■
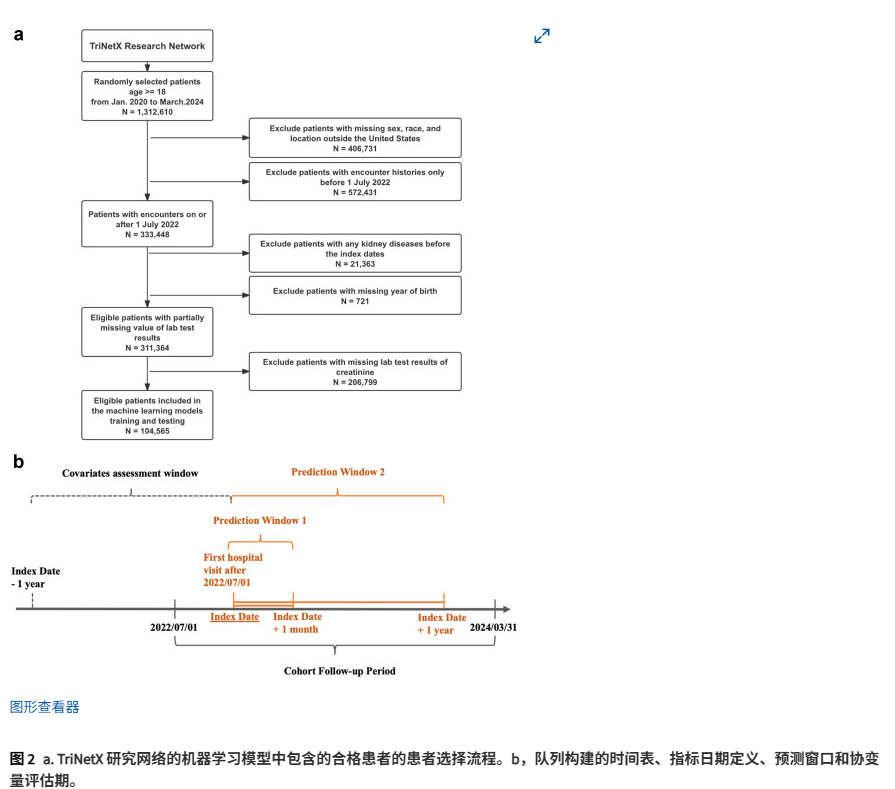
研究数据来自美国TriNetX研究网络的电子健康记录,覆盖2020年1月至2024年3月期间约250家医疗机构的患者。初始样本包括1,312,610名18岁以上患者,经排除缺失人口统计学信息、无2022年7月后就诊记录、已有肾脏疾病史或肌酐值缺失后,最终纳入104,565名患者。
■
研究方法
■
研究采用机器学习模型进行预后分析,包括数据预处理、缺失值填补、类别平衡处理及模型训练。缺失值通过XGBoost算法填补,类别不平衡问题通过SMOTE过采样和随机降采样解决。使用8种机器学习算法(XGBoost、随机森林、神经网络、支持向量机等)训练模型,并通过10折交叉验证和网格搜索优化参数。特征选择结合模型驱动(变量重要性评分)、数据驱动(Spearman相关性降维)和临床驱动(专家意见)方法,最终选定9个关键变量(年龄、性别、BMI、收缩压/舒张压、eGFR、BUN、住院次数、COVID-19感染次数)。模型性能通过AUROC、敏感性、特异性、准确率、F1分数等指标评估,并通过Delong检验比较不同模型的AUROC差异。
■
结果
■
- 研究人群的基线特征 -
经排除标准后,共纳入104,565例患者。其中,101,870例(年龄(平均值,[SD]),52.6 [17.8];女性(%),57.4%)患者在随访期间未发生肾脏结局,366例(年龄,64.1 [15.2];女性,43.7%)患者在1个月内发生AKI,332例(年龄,69.6 [12.7];女性,46.7%)患者在1个月内发生CKD,1,475例(年龄,64.6 [15.3];女性,46.2%)患者在1年内发生AKI,1,642例(年龄,69.1 [13.0];女性,53.8%)患者在1年内发生CKD。与AKI患者1个月预测窗口(65.0 [25.5])、1年预测窗口(72.2 [23.8])和非病例组(91.9 [20.9])相比,CKD患者1个月预测窗口(mL/min/1.73 m2,平均值[SD],51.8 [20.1])和1年预测窗口(58.6 [20.3])内的eGFR最低。一共从EHR中提取了69个变量。
-预测因子的变量重要性-
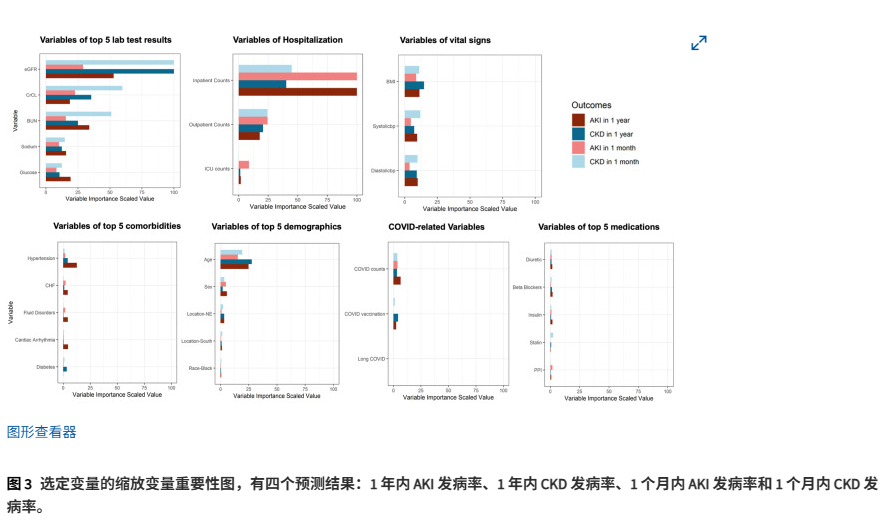
将8种机器学习算法应用于训练数据集,使用所有69个变量进行完整模型训练,分别针对1个月和1年的预测窗口内的AKI和CKD,共计得到32个模型。使用缩放变量重要性(VI)评分进行评估,在1个月和1年的预测窗口中,预测AKI的最重要变量是前一年的住院就诊次数(1个月窗口的VI为100;1年窗口的VI为100),其次是eGFR(29.0;52.8)和BUN(15.6;33.8)。在1个月和1年的预测窗口中,CKD的前三个变量分别是eGFR(100;100)、肌酐清除率(CrCL)(59.8;35.4)和住院次数(45.0;40.4)。在按变量分类的评估亚组中,除了实验室检查结果和住院相关变量外,以下因素在其各自的类别中也显示出重要性:BMI、收缩压、舒张压、高血压、年龄、性别和前一年COVID-19感染人数。
- 模型开发 -
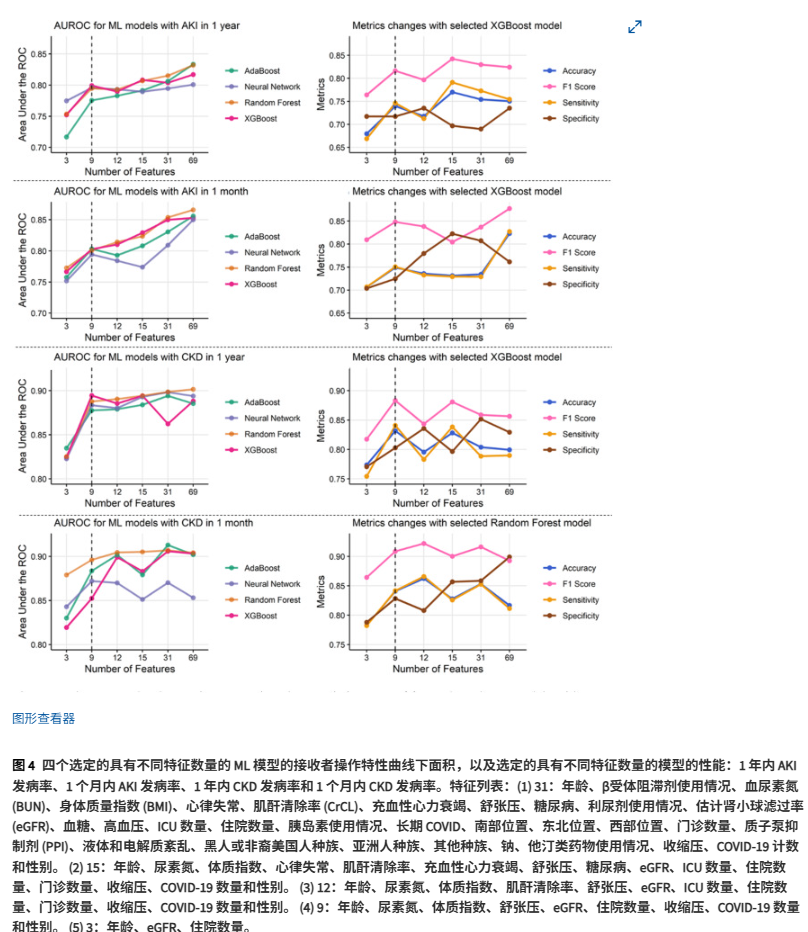
基于模型驱动、数据驱动和临床驱动方法,作者将变量(特征)的数量从69个减少到3个(分别为69、31、15、12、9和3),并分别评估每组ML性能。前4个ML模型的特征和性能列表如图4所示。具体而言,在9个特征时,XGBoost模型在预测1年内AKI、1个月内AKI和1年内CKD方面表现出最佳性能。随机森林模型在9个特征下预测1个月内CKD的效果也最好。然后选择在9个特征处具有最佳AUROC的模型来评估准确性、F1分数、灵敏度和特异性。这些模型展现了良好的性能,在所有评估指标上均未出现显著下降,甚至优于一些包含9个以上特征的模型。因此,作者为最终模型选择了9个特征,包括5个患者人口统计学信息(年龄、性别、BMI、舒张压和收缩压)、2个实验室检查结果(eGFR (mL/min/1.73 m2)和BUN (mg/dL)以及2个过去1年的病史(COVID-19感染次数和住院次数)。
- 模型评估 -
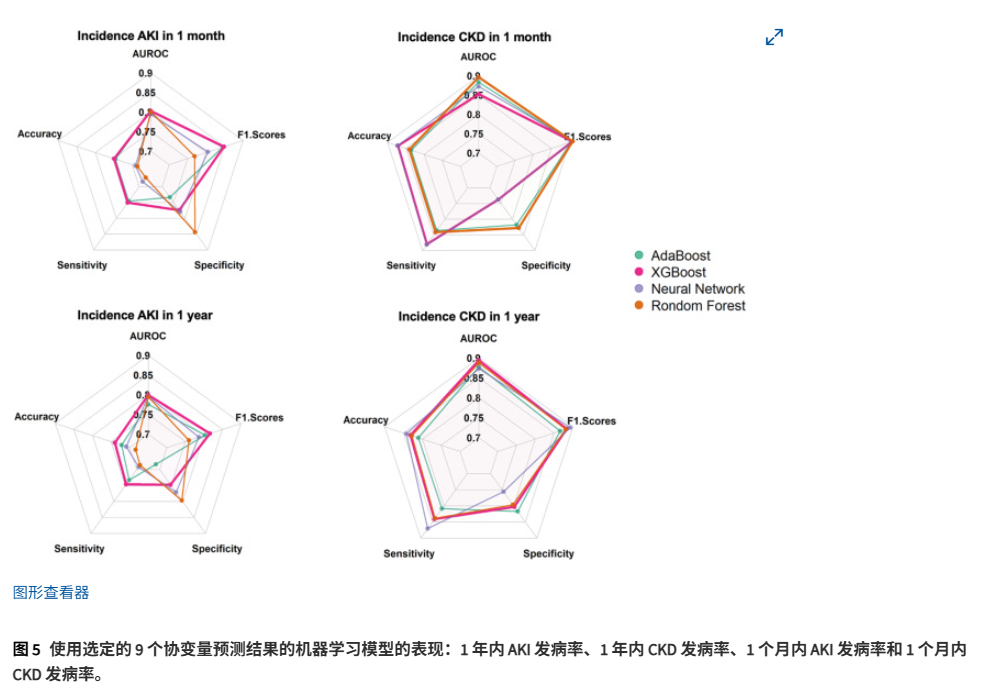
总体而言,四种机器学习模型——AdaBoost、XGBoost、神经网络和随机森林——在使用9个选定特征预测四种结果时表现出色。模型选择主要以AUROC为指导。此外,还寻求在其他标准(包括准确度、F1分数、灵敏度和特异性)之间取得平衡的性能,以确定最终模型。选择XGBoost来预测(1) 1个月窗口内的AKI发病率,AUROC为0.803(95% CI:0.770–0.835),准确度为0.749(0.728–0.771),F1分数为0.848(0.829–0.867),灵敏度为0.751(0.732–0.771),特异性为0.775(0.756–0.793);(2) 1年窗口期内AKI发生率,AUROC为0.799(0.777~0.822),准确度为0.740(0.727~0.760),F1得分为 0.816(0.798~0.834),敏感度为0.746(0.723~0.769),特异度为0.747(0.724~0.771);(3) 1年窗口期内CKD发病率,AUROC为0.894(0.879~0.910),准确率为0.832(0.815~0.848),F1得分为0.883(0.870~0.899),敏感度为0.841(0.821~0.855),特异度为0.803(0.789~0.818)。选择随机森林对1个月窗口期内CKD发病率进行预测,AUROC为0.896(0.864~0.928),准确率为0.841(0.822~0.858),F1得分为0.909(0.881~0.924),敏感度为0.842(0.821~0.864),特异度为0.828(0.803~0.823)。
- 网页应用程序 -
为促进其在临床环境中的应用,作者开发了一个名为AIBI APP的网页应用程序,该应用程序整合了最终模型,用于预测1个月或1年内的AKI和CKD。用户可以通过输入9个选定变量的相应值来获取预测结果(高/低风险)。可通过以下链接访问该应用程序:https://zackzhang1993.shinyapps.io/aibi_app/。
■
结论
■
研究证实,基于大规模国家EHR数据和机器学习模型(XGBoost、随机森林)可高效预测疫情后的AKI和CKD风险,其中COVID-19感染史是关键预测因子。最终模型在简化变量后仍保持高判别性能(AUROC>0.8),且通过网页应用实现了临床转化。
- END -


上一篇:透析患者心脏瓣膜钙化早期筛查机器学习模型的开发和外部验证:一项多中心研究
