2024年,Emily F. Wong等人在《JAMA Network Open》杂志上发表了一篇题为《Evaluating Bias-Mitigated Predictive Models of Perinatal Mood and Anxiety Disorders》的文章。这项研究旨在评估和减少使用常见电子健康记录(EHR)训练的围产期情绪和焦虑障碍(PMADs)预测模型中的偏倚。具体而言,研究的目标是试图开发能够准确预测产后抑郁症筛查结果的机器学习模型,并确保这些模型不会对少数族裔群体产生不利影响,从而减少健康不平等现象。
PMADs是常见的心理健康问题,尤其在产后女性中发病率较高。早期识别和干预对于改善患者的生活质量和预防长期心理问题至关重要。然而,传统的筛查方法可能受到临床偏倚的影响,尤其是在依赖EHR中,这些偏倚可能导致某些群体(如少数族裔)被误诊或漏诊。因此,开发公平且准确的预测模型具有重要意义。
这项研究的数据来源于2020年至2023年期间在洛杉矶锡达斯-西奈医疗中心分娩的19430名患者的EHR。所有患者均为女性,年龄在14至59岁之间,且有活产记录,并在产后入院到产后病房或母胎护理病房。研究中使用的种族信息通过EHR获取,分为以下7个类别:非西班牙裔白人、西班牙裔白人、非裔美国人或非裔黑人、亚裔美国人和太平洋岛民、多种族、其他,以及未提供此信息的患者。
这项诊断性研究旨在预测PMADs,使用了两种常用的筛查工具:9项患者健康问卷(PHQ-9)和爱丁堡产后抑郁量表(EPDS)。将这两个工具的筛查结果分为“低风险”或“中度到高风险”。为了应对类别不平衡问题,研究人员在训练集中对阳性结果(即“中度到高风险”)进行了随机欠采样,以确保模型不会过度拟合多数类数据。研究构建了三种机器学习模型——逻辑回归、随机森林和极端梯度提升(XGBoost),并通过10折交叉验证来评估模型性能,主要评估指标包括曲线下面积(AUROC)、人口统计平等(DP)和假阴性率差异。同时为了优化模型性能,研究使用了树结构Parzen估计器算法,从optuna库中进行超参数调优,以最大化验证集上的AUROC。为了缓解模型中的偏倚,研究引入了“重新加权”的预处理技术,根据Kamiran和Calders的研究提出的公式,计算出样本权重。调整不同种族或民族群体的数据权重,以减少某些群体数据不足的影响,确保模型对所有人群都公平。
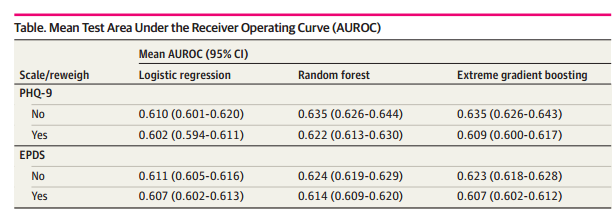
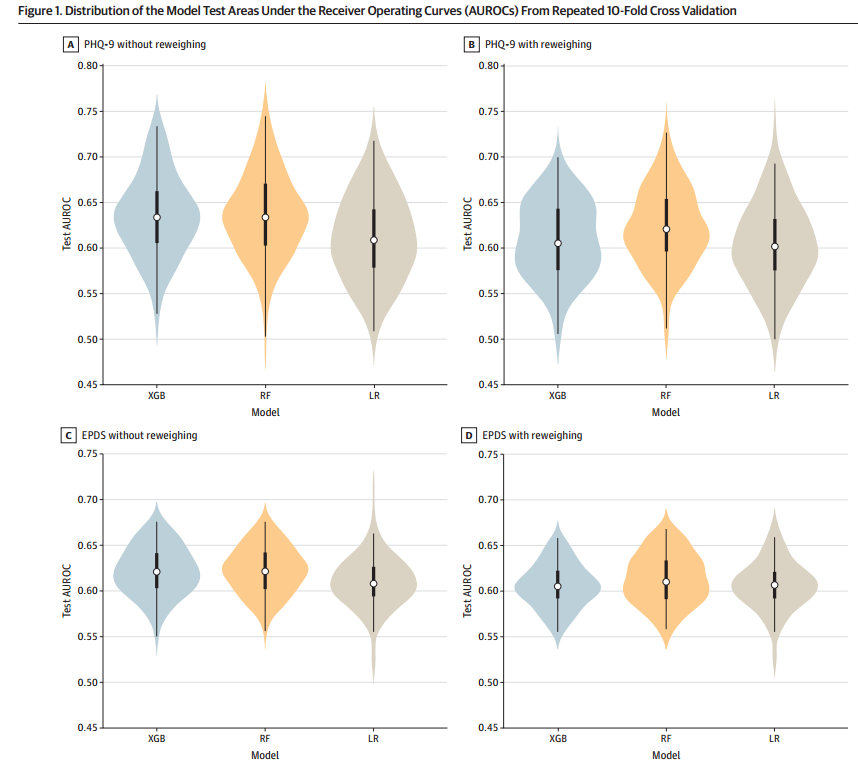
这项研究计算了每个模型在未重新加权和重新加权条件下的平均AUROC及其95%置信区间。结果显示,对于未重新加权的数据,PHQ-9在逻辑回归、随机森林和XGBoost模型的平均测试AUROC分别为0.602、0.622以及0.609,EPDS在逻辑回归、随机森林和XGBoost模型的平均测试AUROC分别为0.607、0.614以及0.607。对于重新加权的数据,PHQ-9在逻辑回归、随机森林和XGBoost模型的平均测试AUROC分别为0.610、0.635以及0.635,EPDS在逻辑回归、随机森林和XGBoost模型的平均测试AUROC分别为0.611、0.624以及0.623。尽管重新加权略微降低了某些模型的整体预测能力(如PHQ-9的XGBoost模型)但模型的AUROC分布总体上仍然保持稳定。这表明重新加权虽然提高了公平性,但略微牺牲了整体预测准确性。(见表1、图1)
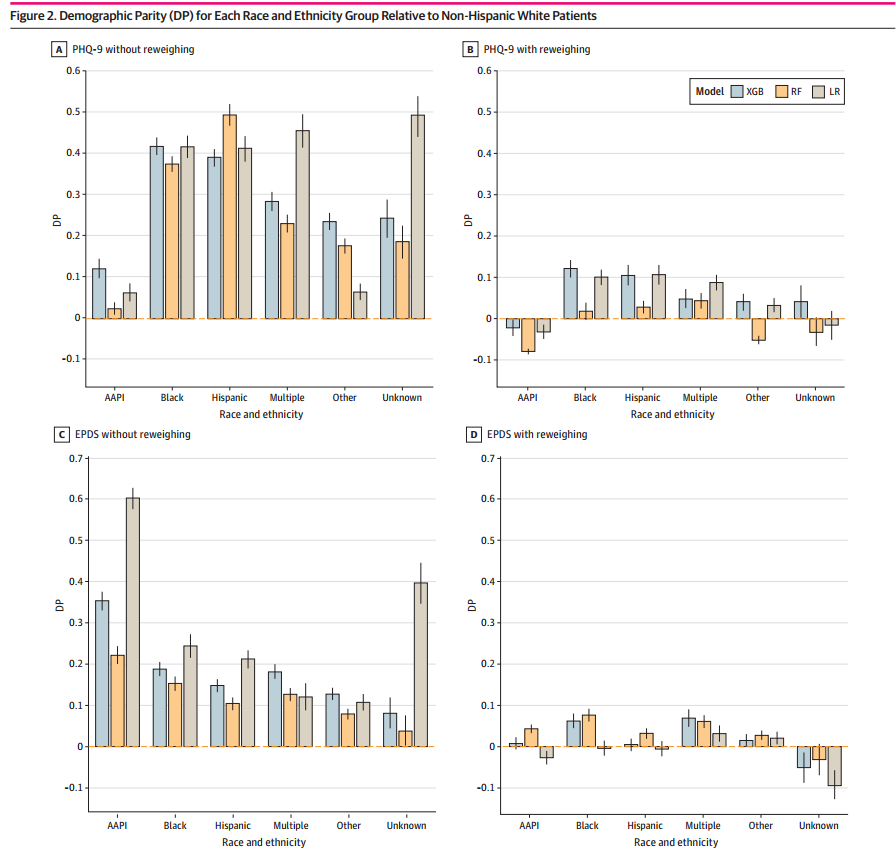
为了评估模型的公平性,研究使用了两个主要的公平性指标,即:DP和假阴性率差异。结果显示,对于未加权的基线模型,少数族裔患者的阳性预测率显著高于非西班牙裔白人患者(DP = 0.238,95% CI: 0.231~0.244,P < 0.001)。这表明,在未重新加权的情况下,模型对少数族裔群体的预测率过高。对于重新加权后的基线模型,显著减少了不同种族之间的DP差异(DP = 0.022,95% CI: 0.017~0.026,P < 0.001)。这表明,重新加权后,模型对不同群体的预测更加公平。(图2)
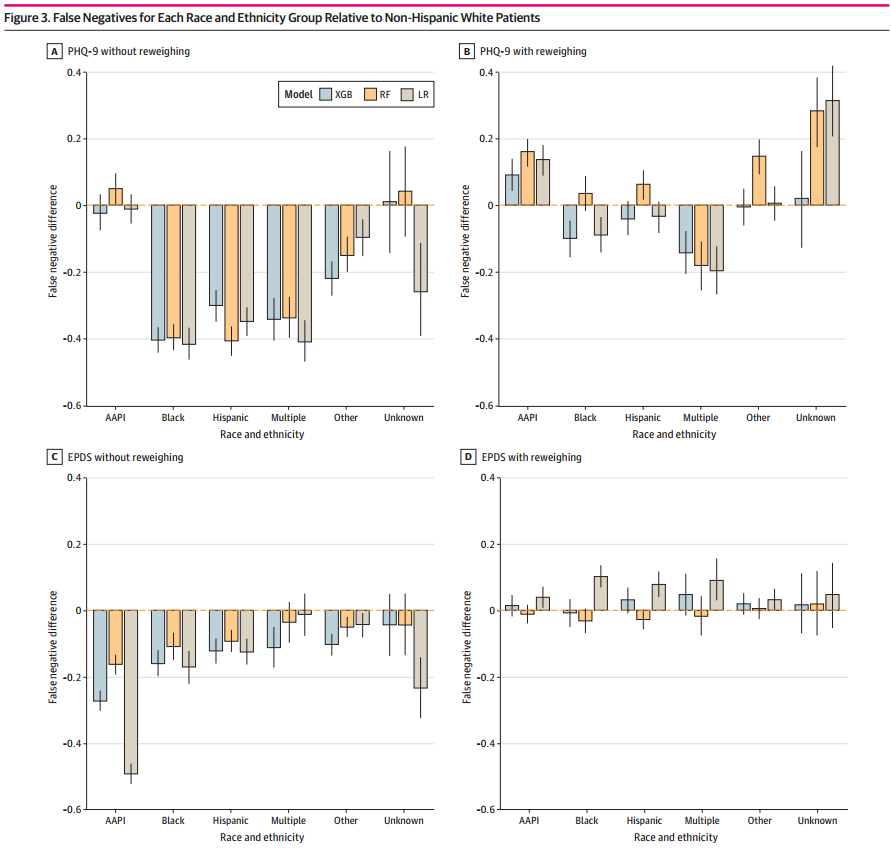
对于未加权的数据,少数族裔患者的假阴性率显著低于非西班牙裔白人患者(假阴性率差异= -0.184,95% CI: -0.195~-0.174,P < 0.001)。这表明,在未重新加权的情况下,模型更容易漏掉少数族裔群体中的PMAD患者。对于重新加权的数据,显著减少了不同种族之间的假阴性率差异(假阴性率差异= 0.018,95% CI: 0.008~0.028,P < 0.001)。这表明,重新加权后,模型对不同群体的预测更加平衡,减少了漏诊的风险。(图3)
为了进一步验证重新加权的效果,研究进行了独立样本t检验。结果显示,重新加权显著降低了DP(P < 0.001)和假阴性率差异(P < 0.001),这些结果表明重新加权技术有效地缓解了模型中的偏倚,提升了模型对不同群体的公平性。
本文通过引入重新加权技术,成功降低了基于电子健康记录(EHR)的围产期情绪和焦虑障碍(PMADs)预测模型中的偏倚,使得模型在不同种族之间的预测更加公平。尽管模型的整体性能仍有提升空间,但这一研究表明,机器学习工具在医疗领域具有重要潜力,尤其是在减少健康不平等方面。未来的研究应继续探索如何优化模型的权重,以实现特定的性能和公平性目标,从而更好地服务于所有患者群体。
— END —
上一篇:孕期鱼类摄入与DHA补充——基于观察性研究的母婴健康影响分析
下一篇:12.09-12.15 临床预测模型研究顶刊快报